Snowpark Container Services Runner Config | DataOps.live
Secrets
Populating the DataOps vault
The vault concepts section describes the DataOps vault in more detail. We recommend you read that page before proceeding any further.
By default, the runner will start with an empty {} vault.yml and a random salt.
Optionally, you can add an initial vault.yml and vault.salt, by adding files to the Orchestrators volume stage
created during runner setup.
- Create your vault files:
echo {} | sudo tee vault.yml > /dev/null
echo $RANDOM | md5sum | head -c 20 | sudo tee vault.salt > /dev/null
-
Update your
vault.ymlas necessary. -
In Snowsight, click "Add Data", and select "Load files into a Stage".
- Select your
vault.ymlandvault.saltfiles to upload and complete the form by selecting the database and schema the runner service belongs to, as well as the stageORCHESTRATOR_VOLUMES. Finally, specify the directory path/secrets/and click "Upload".
Use Snowflake Secrets in a DataOps Project
You can also optionally create Snowflake Secrets and then
reference them in your DataOps.live project. The DataOps Runner for Snowpark Container Services will automatically inject these secrets into the
jobs in your pipeline. Note: this currently only works for Snowflake secrets of type GENERIC_STRING.
Step 1 - Create Snowflake Secrets
You or your data product/engineering teams can create Snowflake secrets in your Snowflake account and give the runner access to them so it can inject them into you pipeline jobs.
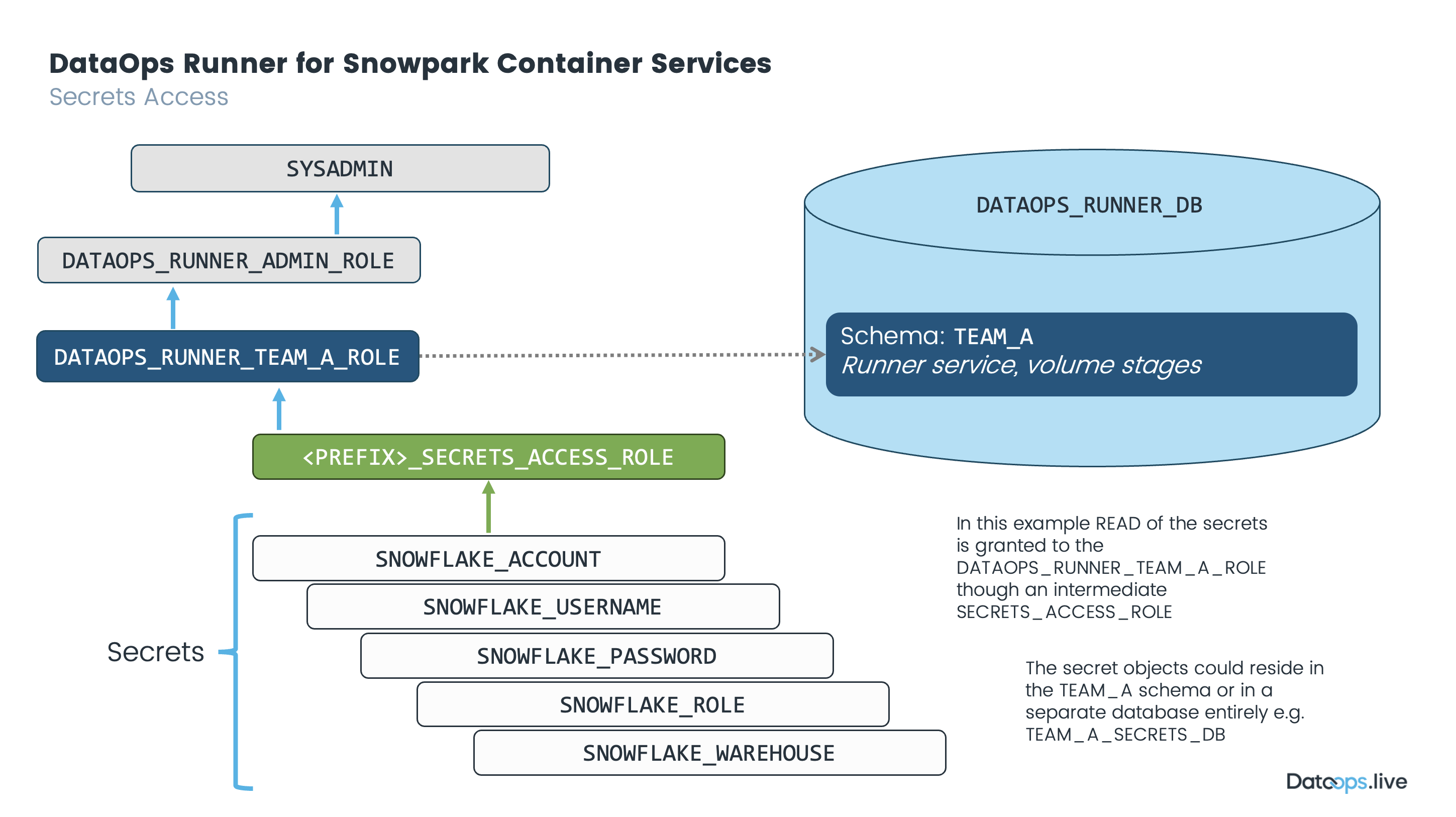
In this example we assume the secrets are being defined in a particular data product team's space e.g. DATA_PRODUCT_TEAM_A_DB.SECRETS_SCHEMA
For example:
USE ROLE SYSADMIN;
USE DATABASE DATA_PRODUCT_TEAM_A_DB;
USE SCHEMA SECRETS_SCHEMA;
CREATE OR REPLACE SECRET SNOWFLAKE_ACCOUNT TYPE=GENERIC_STRING SECRET_STRING='account_name'; -- changeme
CREATE OR REPLACE SECRET SNOWFLAKE_USERNAME TYPE=GENERIC_STRING SECRET_STRING='DATAOPS_SOLE_ADMIN';
CREATE OR REPLACE SECRET SNOWFLAKE_PASSWORD TYPE=GENERIC_STRING SECRET_STRING='******************'; -- changeme
CREATE OR REPLACE SECRET SNOWFLAKE_ROLE TYPE=GENERIC_STRING SECRET_STRING='DATAOPS_SOLE_ADMIN_ROLE';
CREATE OR REPLACE SECRET SNOWFLAKE_WAREHOUSE TYPE=GENERIC_STRING SECRET_STRING='DATAOPS_SOLE_ADMIN_WAREHOUSE';
Whoever creates the secrets should ensure that the runner has access to them.
The runner should have the necessary privileges granted to its secret access role. e.g. DATAOPS_RUNNER_TEAM_A_SECRETS_ACCESS_ROLE
For example:
USE ROLE SYSADMIN;
CREATE ROLE IF NOT EXISTS DATAOPS_RUNNER_TEAM_A_SECRETS_ACCESS_ROLE;
GRANT ROLE DATAOPS_RUNNER_TEAM_A_SECRETS_ACCESS_ROLE TO ROLE DATAOPS_RUNNER_TEAM_A_ROLE;
GRANT USAGE ON DATABASE DATA_PRODUCT_TEAM_A_DB TO ROLE DATAOPS_RUNNER_TEAM_A_SECRETS_ACCESS_ROLE;
GRANT USAGE ON SCHEMA SECRETS_SCHEMA TO ROLE DATAOPS_RUNNER_TEAM_A_SECRETS_ACCESS_ROLE;
GRANT READ ON SECRET DATA_PRODUCT_TEAM_A_DB.SECRETS_SCHEMA.SNOWFLAKE_ACCOUNT TO ROLE DATAOPS_RUNNER_TEAM_A_SECRETS_ACCESS_ROLE;
GRANT READ ON SECRET DATA_PRODUCT_TEAM_A_DB.SECRETS_SCHEMA.SNOWFLAKE_USERNAME TO ROLE DATAOPS_RUNNER_TEAM_A_SECRETS_ACCESS_ROLE;
GRANT READ ON SECRET DATA_PRODUCT_TEAM_A_DB.SECRETS_SCHEMA.SNOWFLAKE_PASSWORD TO ROLE DATAOPS_RUNNER_TEAM_A_SECRETS_ACCESS_ROLE;
GRANT READ ON SECRET DATA_PRODUCT_TEAM_A_DB.SECRETS_SCHEMA.SNOWFLAKE_ROLE TO ROLE DATAOPS_RUNNER_TEAM_A_SECRETS_ACCESS_ROLE;
GRANT READ ON SECRET DATA_PRODUCT_TEAM_A_DB.SECRETS_SCHEMA.SNOWFLAKE_WAREHOUSE TO ROLE DATAOPS_RUNNER_TEAM_A_SECRETS_ACCESS_ROLE;
Step 2 - Reference the secrets in your DataOps Project
The implementation of resolving secrets is subject to change.
In your DataOps.live project, you can look up Snowflake secrets and convert them to job variables as follows:
variables:
SECRETS_MANAGER: "none"
SNOWFLAKE_SECRET_LOOKUP_01: "do://snowflake/DATA_PRODUCT_TEAM_A_DB.SECRETS_SCHEMA.SNOWFLAKE_ACCOUNT"
SNOWFLAKE_SECRET_LOOKUP_02: "do://snowflake/DATA_PRODUCT_TEAM_A_DB.SECRETS_SCHEMA.SNOWFLAKE_USERNAME"
SNOWFLAKE_SECRET_LOOKUP_03: "do://snowflake/DATA_PRODUCT_TEAM_A_DB.SECRETS_SCHEMA.SNOWFLAKE_PASSWORD"
SNOWFLAKE_SECRET_LOOKUP_04: "do://snowflake/DATA_PRODUCT_TEAM_A_DB.SECRETS_SCHEMA.SNOWFLAKE_ROLE"
SNOWFLAKE_SECRET_LOOKUP_05: "do://snowflake/DATA_PRODUCT_TEAM_A_DB.SECRETS_SCHEMA.SNOWFLAKE_WAREHOUSE"
First, we skip using a secrets manager and resolve variables from the Snowflake secrets directly. Thus, we use SECRETS_MANAGER: "none".
Second, the names of variables you use to look up a given secret can be anything but the secret name. In the examples, we used SNOWFLAKE_SECRET_LOOKUP_NN.
The lookup will search for variable values that start with the string do://snowflake/ and use the rest of the string as the Snowflake secret name to resolve.
Further, the Snowflake secret name is then passed as a job variable of the same name to the jobs to be executed.
When executed, the example will create the variables:
SNOWFLAKE_ACCOUNT: value from snowflake secret
SNOWFLAKE_USERNAME: value from snowflake secret
SNOWFLAKE_PASSWORD: value from snowflake secret
SNOWFLAKE_ROLE: value from snowflake secret
SNOWFLAKE_WAREHOUSE: value from snowflake secret
The reason they can't be the same is that the variables in the variables.yml take precedence over the injected secrets.
Consider the following example:
variables:
SNOWFLAKE_SECRET_LOOKUP_03: "do://snowflake/DATA_PRODUCT_TEAM_A_DB.SECRETS_SCHEMA.SNOWFLAKE_PASSWORD"
# or
MY_REFERENCE_FOR_SOLE_PASSWORD: "do://snowflake/DATA_PRODUCT_TEAM_A_DB.SECRETS_SCHEMA.SNOWFLAKE_PASSWORD"
Both produce the same result: the env variable SNOWFLAKE_PASSWORD in the jobs will be the value of the snowflake secret named "SNOWFLAKE_PASSWORD".
Don't do this:
variables:
SNOWFLAKE_PASSWORD: "do://snowflake/DATA_PRODUCT_TEAM_A_DB.SECRETS_SCHEMA.SNOWFLAKE_PASSWORD"
Because the env variable SNOWFLAKE_PASSWORD in the jobs will retain the string value "do://snowflake/SNOWFLAKE_PASSWORD".
Step 3 - Reference the secrets in your DataOps Project
Finally, you may need to update your vault.template.yml file in your project to populate the
DataOps Vault for use by some orchestrators, such as the SOLE and MATE orchestrator.
SNOWFLAKE:
ACCOUNT: "{{ env.SNOWFLAKE_ACCOUNT }}"
SOLE:
ACCOUNT: "{{ env.SNOWFLAKE_ACCOUNT }}"
USERNAME: "{{ env.SNOWFLAKE_USERNAME }}"
PASSWORD: "{{ env.SNOWFLAKE_PASSWORD }}"
ROLE: "{{ env.SNOWFLAKE_ROLE }}"
WAREHOUSE: "{{ env.SNOWFLAKE_WAREHOUSE }}"
TRANSFORM:
USERNAME: "{{ env.SNOWFLAKE_USERNAME }}"
PASSWORD: "{{ env.SNOWFLAKE_PASSWORD }}"
ROLE: "{{ env.SNOWFLAKE_ROLE }}"
WAREHOUSE: "{{ env.SNOWFLAKE_WAREHOUSE }}"
For a SOLE job to work, you either need to have the variables DATAOPS_SOLE_XXX set or have the keys SNOWFLAKE.SOLE.XXX set in the DataOps vault.
Since our examples used the Snowflake secret SNOWFLAKE_XXX, we mapped them to the vault keys SNOWFLAKE.SOLE.XXX with the YAML file shown.
Similarly, for MATE jobs to work, we require SNOWFLAKE.TRANSFORM.XXX DataOps vault keys to be present. Again, we map them from the
Snowflake secret SNOWFLAKE_XXX.
Using the vault protects your credentials at runtime. Credentials are stored encrypted during pipeline execution and masked in log files.
Once you mapped the variables to the vault hierarchy, you can use them in any job definition using the standard DATAOPS_VAULT() function. For example:
my job:
variables:
ACCOUNT: DATAOPS_VAULT(SNOWFLAKE.ACCOUNT)
Restrictive Network Rule
In the Create an Access Integration step of the installation instructions, you create a network rule to allow the runner to connect to the Snowflake and DataOps platforms.
The Network Rule used in the setup instructions allows all outbound HTTP and HTTPS connections. However, if you want to restrict the outbound connections to specific domains, you can create a more restrictive network rule. For example:
CREATE NETWORK RULE IF NOT EXISTS ALLOW_RESTRICTED_RULE
TYPE = 'HOST_PORT'
MODE= 'EGRESS'
VALUE_LIST = ('myaccount.registry.snowflakecomputing.com', 'myaccount.snowflakecomputing.com', 'app.dataops.live', 'dataops-artifacts-production.s3.eu-west-2.amazonaws.com', 'hub.docker.com', 'registry-1.docker.io', 'auth.docker.io', 'production.cloudflare.docker.com');
USE ROLE ACCOUNTADMIN;
CREATE OR REPLACE EXTERNAL ACCESS INTEGRATION DATAOPS_ALLOW_RESTRICTED_INTEGRATION
ALLOWED_NETWORK_RULES = (ALLOW_RESTRICTED_RULE)
ENABLED = true;
GRANT OWNERSHIP ON ACCESS INTEGRATION DATAOPS_ALLOW_RESTRICTED_INTEGRATION TO ROLE DATAOPS_RUNNER_ADMIN_ROLE
COPY CURRENT GRANTS;
Don't forget to change myaccount in the snowflakecomputing.com domains to your account.
Notes:
- Creates a network rule named
ALLOW_RESTRICTED_RULE.- The
VALUE_LISTcontains the minimum required domains for the runner to access the DataOps.live platform and your Snowflake account. You may need to update theVALUE_LISTdepending on what external services your pipeline jobs call out to.
- The
- Creates an external access integration named
DATAOPS_ALLOW_RESTRICTED_INTEGRATION. - During setup of a runner, remember to reference
DATAOPS_ALLOW_RESTRICTED_INTEGRATIONinstead of the defaultDATAOPS_ALLOW_ALL_INTEGRATION.