Assist Data Pipeline mode for Data Engineers
Data Pipeline mode supports modern data engineering workflows. It helps you:
- Design robust, scalable data pipelines
- Optimize pipeline performance across stages
- Build error handling and recovery mechanisms directly into your pipelines
Building each pipeline component from scratch takes time, and data engineers often have higher-priority tasks. The DataOps.live reference project simplifies this process by generating a standardized project structure from a template. You can then customize the template to fit your specific needs.
However, the reference project only provides scaffolding, it doesn’t tailor pipelines to your requirements. That’s where Data Pipeline mode steps in.
With Data Pipeline mode, you define your requirements, and Assist generates a tailored pipeline for you. For example, prompting: “Create a simple environment pipeline job” creates a new YAML file and generates the following job:
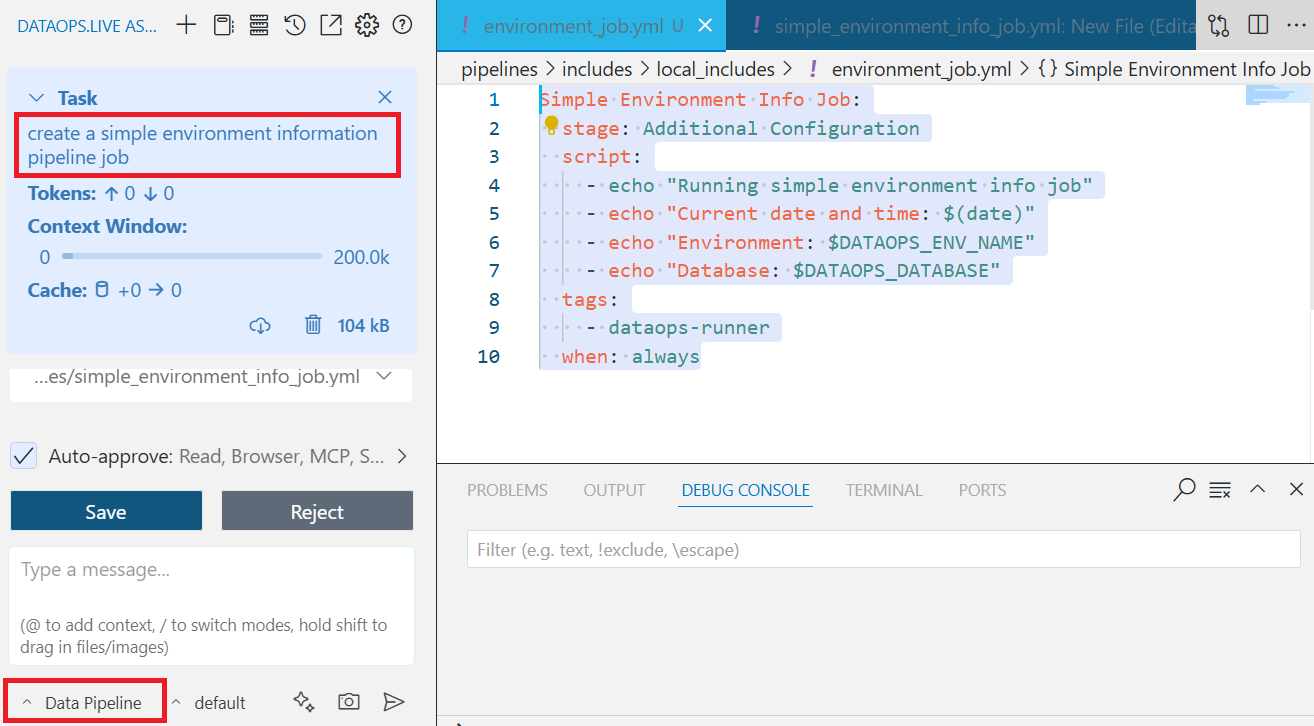
Simple Environment Info Job:
extends:
- .agent_tag
stage: Additional Configuration
script:
- echo "Running simple environment info job"
- echo "Current date and time: $(date)"
- echo "Environment: $DATAOPS_ENV_NAME"
- echo "Database: $DATAOPS_DATABASE"
tags:
- dataops-runner
when: always
This job captures and prints basic environment details during pipeline execution. It runs in the Additional Configuration stage and triggers on every pipeline run, regardless of success or failure in previous steps (when: always).
You can use it to debug, audit, or validate configuration settings before other stages run. It logs:
- The current date and time
- The active DataOps environment name (
$DATAOPS_ENV_NAME) - The target database (
$DATAOPS_DATABASE)
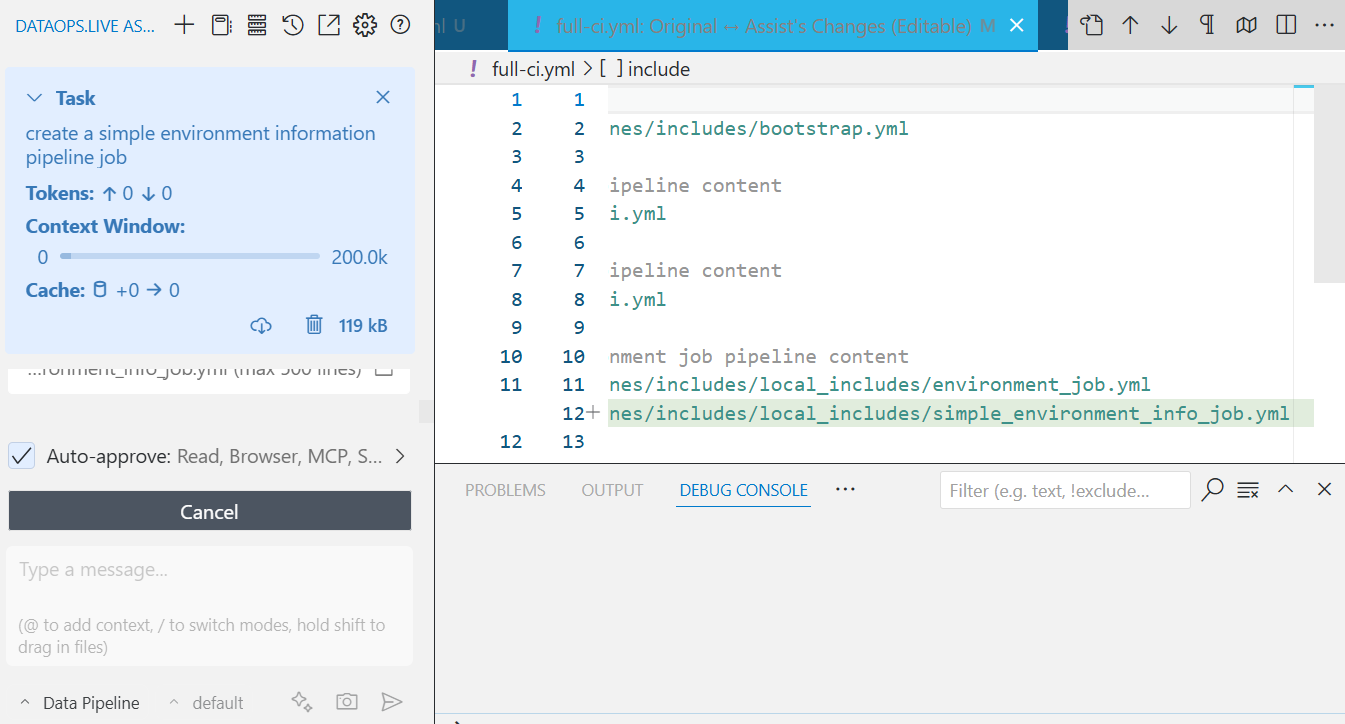
Next, Assist asks you for permission to include this job in your full-ci.yml file—the main pipeline configuration. Once you confirm and save, it automatically adds the job to your CI workflow.