DataOps.live Core Concepts
Understanding how we use the following terms and concepts within DataOps.live as both a philosophy and platform is important. Here is a list of the essential concepts and terms found within the data product platform:
Account and project structure
DataOps projects are functionally similar to repositories in other VCS platforms and are typically contained in a group/subgroup structure within a client account.
Account/Top-level group
An account is effectively a customer tenant within the data product platform and is materialized as a top-level group in the organizational structure. It contains the following:
Therefore, a typical account URL will look something like https://app.dataops.live/acme-corp.
A DataOps user is assigned to an account (by DataOps.live staff) as a member, granting account-level access at different privilege levels.
Group/Subgroup
A group is a collection of the following items:
These items are all contained within an account.
Group owners can assign other DataOps users access to each group (as members), assigning each with different privilege levels.
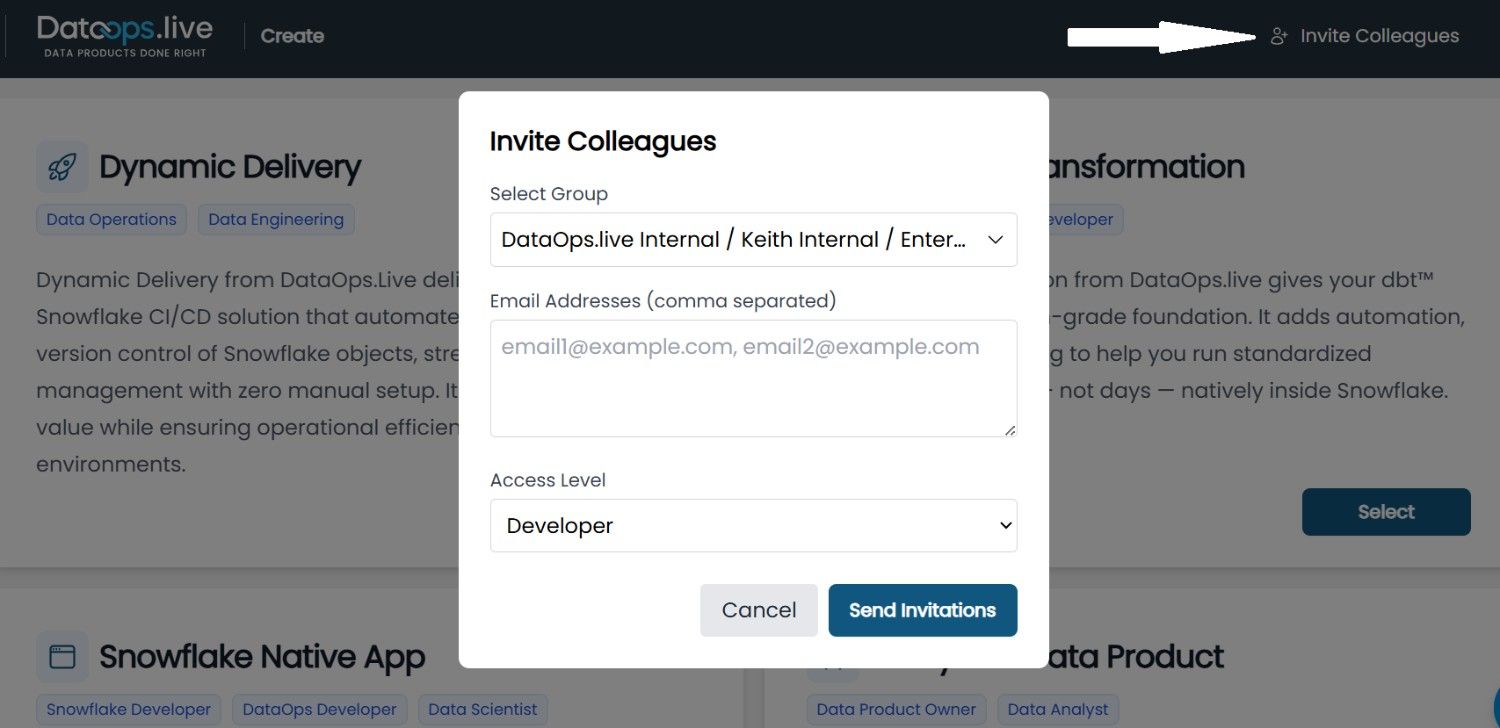
A simple way to grant users access to different groups with specific privilege levels is through the +Invite Colleagues feature in the UI.
- On the DataOps Create page, select the "Invite Colleagues" option in the top-right corner.
- In the pop-up window, choose the group you want to add users to, then enter their email address. If you enter personal email addresses, the system prompts you to confirm. Select Yes, Invite External Users to proceed.
- Next, assign an access level: Guest, Reporter, or Developer. Each role provides the appropriate privileges to the invitee.
It is usually best practice to register a DataOps runner against a group rather than projects.
Project
A project is primarily a Git-compliant code repository that contains configurations allowing code to be merged and pipelines to be run.
You can create projects at the top level of an account. However, creating projects within groups/sub-groups is good practice.
User
A user is a login that permits a physical person (or system user) entry to the data product platform. Users are created by DataOps.live staff and assigned to an account or independently by customers if they have set up Single Sign-On (SSO), bypassing the need for assistance from DataOps.live staff.
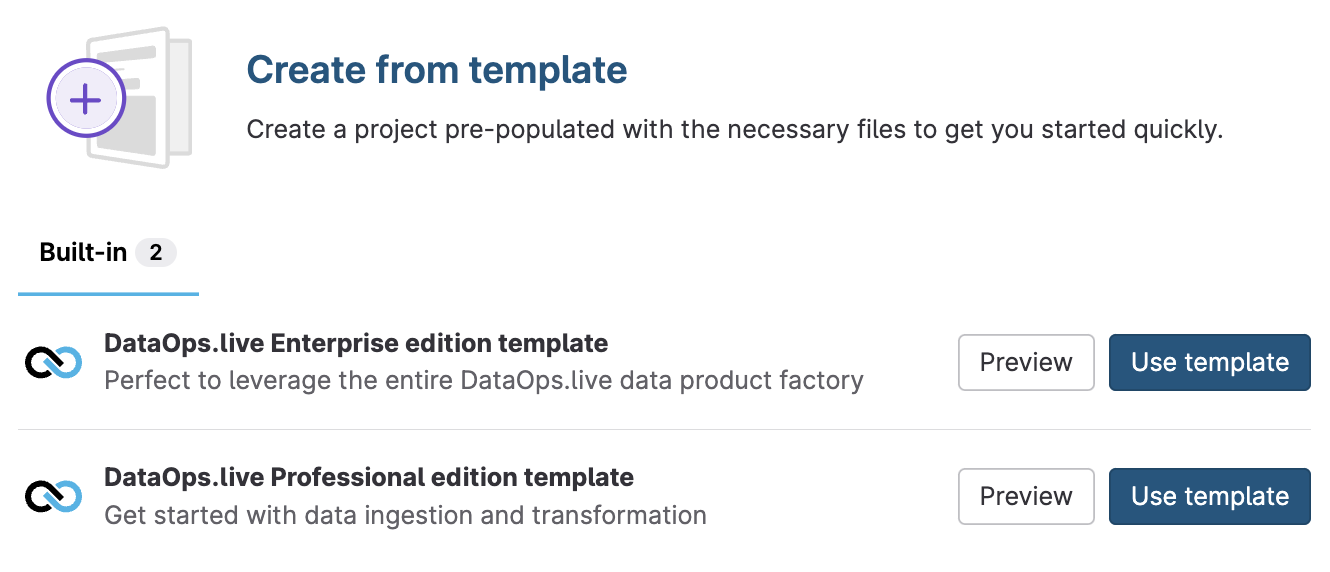
Template project
When setting up any new DataOps projects, the DataOps administrator will typically create a new project from the Enterprise edition template rather than starting from scratch. This brings in the standard structure, mandatory directories and files, and many best-practice configurations. For Professional Customers, we have a Professional edition template.
Reference project
To avoid repeatedly copying and maintaining many standard configuration files, each DataOps project maintains a link to the standard DataOps Reference Project. This includes standard pipeline configuration settings, such as stages, default jobs, etc., and clones the entire settings into the runtime workspace within each pipeline, providing much more project content.
DataOps pipelines
All execution of DataOps code happens within DataOps pipelines that comprise a series of individual jobs.
Pipeline

A DataOps Pipeline is an execution of a pipeline file in a project that runs the pipeline's configured jobs in the specified stage.
Pipeline file
One of the main YAML configuration files within DataOps projects, each pipeline file (a project can have one or many) is identified by a suffix of -ci.yml, e.g., full-ci.yml.
Pipeline files must sit at the top level in the project, not in a subdirectory.
Job
Each pipeline file includes one or more jobs, whether defined in the project itself (usually as a YAML file within pipelines/includes), or within a DataOps reference project.

Job definitions must include the following:
- A pipeline file
- A stage
- Other configurations to determine where and how the job will run.
Base job
Many jobs often share similar configurations. For example, several MATE jobs may use the same image, stage, and variables. To prevent duplicating the same code and saving the same configuration into each job, the principle of reusable code is applied where a base job provides an abstract job definition that will not directly run but is included in other jobs to prevent repeated content.
Base jobs are identified by a leading dot (.) in front of the filename - e.g. .modelling_and_transformation_base.
Pipeline stages
The fundamental method for sequencing jobs in a pipeline is through stages. A project defines a series of stage names in a configuration file, and then each job is configured to run in one of these stages.
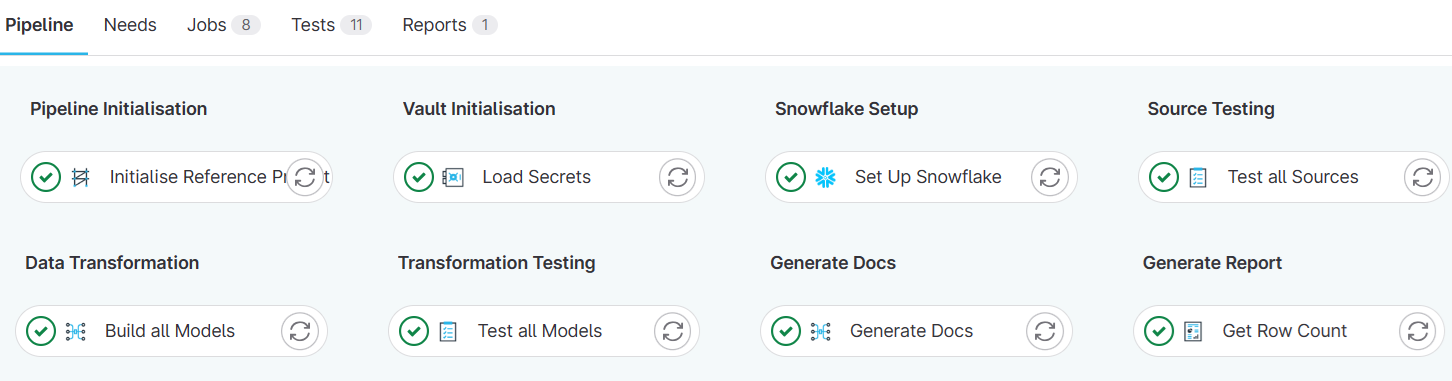
All the jobs in any given stage will execute in parallel, up to the concurrency limits of the DataOps runner.
Variables
Within pipeline configuration files, variables that control the behavior of the DataOps pipelines and its individual jobs are defined. These variables are passed into a job orchestrator image at execution time and are added to the runtime environment for access by apps and scripts.
Runtime infrastructure
DataOps runner
The DataOps Runner is a lightweight, long-running Docker container that a DataOps administrator will install on client infrastructure (usually a cloud or on-premises virtual machine) that picks up and runs the jobs within DataOps pipelines.
Jobs that run on the DataOps Runner are instantiated as additional, short-lived orchestrators.
You can use the term runner synonymously to refer to both a logical runner process (Docker container) and the physical/virtual machine it runs on.
Orchestrators
Orchestrators execute the workload of specific DataOps pipeline jobs and are launched by the DataOps runner as a subprocess of the DataOps runner.
When configuring a DataOps job, the developer must select the most appropriate orchestrator for the required task. Each orchestrator is defined by an Orchestrator container image, available as a predefined variable in the DataOps Reference Project.
The orchestrator container image contains all the necessary tools and scripts to execute the job.
The DataOps runner and DataOps orchestrators interact as follows:

The default polling interval of the runner for new work is 10 seconds and can be altered during runner installation by modifying the check_interval in the generated config.toml.
Vault
Each time a pipeline runs, DataOps automatically creates a secure, encrypted file known as the DataOps Vault, which resides only on the DataOps runner host. It is populated by vault files on the runner host and by configuration from a secrets manager if one is configured in the DataOps project.
Jobs can access information from the vault using variable substitution in template files, e.g., {{ SNOWFLAKE.ACCOUNT }}, or setting variables using the DATAOPS_VAULT(...) syntax.