Stage Ingestion Orchestrator
Professional Enterprise
| Image | $DATAOPS_STAGEINGESTION_RUNNER_IMAGE |
|---|---|
| Feature Status | PubPrev |
The Stage Ingestion orchestrator ingests data from Snowflake stages into tables defined in the Snowflake configuration.
Multiple tables may be ingested, and these will run in parallel.
Usage
You must use the Stage Ingestion orchestrator with SOLE for Data Products. SOLE will create the tables, file formats, and stages the Stage Ingestion orchestrator needs.
The preview release currently supports ingestion from AWS S3 stages created by SOLE.
Supported parameters
| Parameter | Required/Default | Description |
|---|---|---|
DATAOPS_DIRECT_INGESTION_ACTION | REQUIRED | Must be START |
CONFIGURATION_DIR | REQUIRED | Set to $CI_PROJECT_DIR/dataops/snowflake to read the default Snowflake configuration files |
DATAOPS_SOLE_ACCOUNT | REQUIRED | The Snowflake account name to use |
DATAOPS_SOLE_USERNAME | REQUIRED | The Snowflake username to use |
DATAOPS_SOLE_PASSWORD | REQUIRED | The Snowflake password to use |
DATAOPS_SOLE_ROLE | REQUIRED | The Snowflake role to use |
DATAOPS_SOLE_WAREHOUSE | REQUIRED | The Snowflake warehouse to use |
Below is a typical job definition:
Stage Ingestion:
extends:
- .agent_tag
- .should_run_ingestion
image: $DATAOPS_STAGEINGESTION_RUNNER_IMAGE
stage: "Batch Ingestion"
variables:
DATAOPS_STAGE_INGESTION_ACTION: START
CONFIGURATION_DIR: $CI_PROJECT_DIR/dataops/snowflake
# Adjust the values below if required, to ingest as the appropriate user/role
DATAOPS_SOLE_ACCOUNT: DATAOPS_VAULT(SNOWFLAKE.ACCOUNT)
DATAOPS_SOLE_USERNAME: DATAOPS_VAULT(SNOWFLAKE.TRANSFORM.USERNAME)
DATAOPS_SOLE_PASSWORD: DATAOPS_VAULT(SNOWFLAKE.TRANSFORM.PASSWORD)
DATAOPS_SOLE_ROLE: DATAOPS_VAULT(SNOWFLAKE.TRANSFORM.ROLE)
DATAOPS_SOLE_WAREHOUSE: DATAOPS_VAULT(SNOWFLAKE.TRANSFORM.WAREHOUSE)
# prevent parallel ingestion for the same tables on the same branch
resource_group: $CI_JOB_NAME
script:
- /dataops
icon: ${SNOWFLAKEOBJECTLIFECYCLE_ICON}
Configuration tables for ingestion
You can configure the tables to be ingested in the Snowflake configuration files, which SOLE also reads. For each table, you can define an orchestrators: section.
This section contains a stage_ingestion: section defining the ingestion parameters. Supported parameters are:
| Parameter | Required/Default | Description |
|---|---|---|
stage | REQUIRED | The stage name containing the data. Currently, this must be in the same schema as the destination table. |
file_format | REQUIRED | The file format name to be used to process the data. Currently, this must be in the same schema as the destination table. |
path | REQUIRED | The path to the data file(s) inside the stage. This is appended to the stage name in the COPY INTO command. |
method | Optional. Defaults to append | append or full_load. full_load will truncate the table before ingestion. Not yet implemented. |
truncate | Optional. Defaults to false | true or false. Whether to truncate before ingestion. To be removed in a future release. |
copy | Optional | A key-value pair dictionary of options to be passed to the Snowflake COPY INTO command. See copy parameters for a definition of copy |
pattern | Optional | A regular expression pattern string, enclosed in single quotes, specifying the file names and/or paths to match. |
COPY INTO <table>
copy parameters
The copy parameter supports the following parameters:
| Configuration Key | Required/Optional | Data Types and Values |
|---|---|---|
size_limit | Optional | Integer |
force | Optional | Boolean |
purge | Optional | Boolean |
return_failed_length | Optional | Boolean |
enforce_length | Optional | Boolean |
truncatecolumns | Optional | Boolean |
load_uncertain_files | Optional | Boolean |
match_by_column_name | Optional | String: CASE_SENSITIVE, CASE_INSENSITIVE, NONE |
See the Snowflake doc section for more information.
An example is shown below:
- Default Configuration
- Data Products Configuration
databases:
"{{ env.DATAOPS_DATABASE }}":
schemas:
SCHEMA1:
tables:
NASA_PATENTS:
columns:
CENTER:
type: TEXT
STATUS:
type: TEXT
CASE_NUMBER:
type: TEXT
PATENT_NUMBER:
type: VARCHAR(255)
APPLICATION_SN:
type: TEXT
TITLE:
type: TEXT
PATENT_EXPIRATION_DATE:
type: DATE
_METADATA_FILENAME:
type: VARCHAR(255)
_METADATA_ROWNUM:
type: NUMBER(38,0)
_METADATA_INGEST_DATE:
type: TIMESTAMP_NTZ(9)
orchestrators:
stage_ingestion:
stage: DOL_SOURCE_BUCKET
file_format: CSV_FORMAT
path: csv/NASA_Patents.csv
truncate: true
copy:
force: true
DISCHARGE_REPORT_BY_CODE_MS_2:
columns:
GEOGRAPHIC_UNIT:
type: TEXT
STUDENT_CATEGORY:
type: TEXT
CODE:
type: TEXT
CODE_TYPE:
type: TEXT
DESCRIPTION_OF_CODE:
type: TEXT
COUNT_OF_STUDENTS:
type: VARCHAR(255)
TOTAL_ENROLLED_STUDENTS:
type: NUMBER
orchestrators:
stage_ingestion:
stage: SOURCE_STAGE
file_format: CSV_FORMAT
PATH: csv
PATTERN: ".*/.*/.*[.]csv"
truncate: true
copy:
force: true
size_limit: 6000
purge: true
return_failed_length: true
enforce_length: true
truncatecolumns: false
load_uncertain_files: true
BEHAVIORAL_RISK_FACTOR_SURVEILLANCE_SYSTEM:
columns:
DATA:
type: VARIANT
orchestrators:
stage_ingestion:
stage: SOURCE_STAGE
file_format: PARQUET_FORMAT
PATH: parquet/Behavioral_Risk_Factor_Surveillance_System__BRFSS__Prevalence_Data__2011_to_present_.parquet
truncate: true
copy:
force: true
ASSET_OUTAGE:
comment: "assetOutage from eNAMS"
columns:
JSON_DATA:
type: VARIANT
orchestrators:
stage_ingestion:
stage: external_data_stage
file_format: JSON_FORMAT
file_type: json
path: json/history_asset_outage.json
truncate: true
copy:
force: true
- database:
name: "{{ env.DATAOPS_DATABASE }}"
- schema:
name: SCHEMA1
database: rel(database.{{env.DATAOPS_DATABASE }})
- table:
name: NASA_PATENTS
database: rel(database.{{ env.DATAOPS_DATABASE }})
schema: rel(schema.SCHEMA1)
columns:
CENTER:
type: TEXT
STATUS:
type: TEXT
CASE_NUMBER:
type: TEXT
PATENT_NUMBER:
type: VARCHAR(255)
APPLICATION_SN:
type: TEXT
TITLE:
type: TEXT
PATENT_EXPIRATION_DATE:
type: DATE
_METADATA_FILENAME:
type: VARCHAR(255)
_METADATA_ROWNUM:
type: NUMBER(38,0)
_METADATA_INGEST_DATE:
type: TIMESTAMP_NTZ(9)
orchestrators:
stage_ingestion:
stage: DOL_SOURCE_BUCKET
file_format: CSV_FORMAT
path: csv/NASA_Patents.csv
truncate: true
copy:
force: true
- table:
name: DISCHARGE_REPORT_BY_CODE_MS_2
database: rel(database.{{ env.DATAOPS_DATABASE }})
schema: rel(schema.SCHEMA1)
columns:
GEOGRAPHIC_UNIT:
type: TEXT
STUDENT_CATEGORY:
type: TEXT
CODE:
type: TEXT
CODE_TYPE:
type: TEXT
DESCRIPTION_OF_CODE:
type: TEXT
COUNT_OF_STUDENTS:
type: VARCHAR(255)
TOTAL_ENROLLED_STUDENTS:
type: NUMBER
orchestrators:
stage_ingestion:
stage: SOURCE_STAGE
file_format: CSV_FORMAT
PATH: csv
PATTERN: ".*/.*/.*[.]csv"
truncate: true
copy:
force: true
size_limit: 6000
purge: true
return_failed_length: true
enforce_length: true
truncatecolumns: false
load_uncertain_files: true
- table:
name: BEHAVIORAL_RISK_FACTOR_SURVEILLANCE_SYSTEM
database: rel(database.{{ env.DATAOPS_DATABASE }})
schema: rel(schema.SCHEMA1)
columns:
DATA:
type: VARIANT
orchestrators:
stage_ingestion:
stage: SOURCE_STAGE
file_format: PARQUET_FORMAT
PATH: parquet/Behavioral_Risk_Factor_Surveillance_System__BRFSS__Prevalence_Data__2011_to_present_.parquet
include_metadata: true | false
method: append | full_load
post_hook: sql|shell
truncate: true
copy:
force: true
match_by_column_name: CASE_INSENSITIVE
- table:
name: ASSET_OUTAGE
database: rel(database.{{ env.DATAOPS_DATABASE }})
schema: rel(schema.SCHEMA1)
columns:
JSON_DATA:
type: VARIANT
orchestrators:
stage_ingestion:
stage: SOURCE_STAGE
file_format: JSON_FORMAT
file_type: json
path: json/history_asset_outage.json
truncate: true
copy:
force: true
match_by_column_name: CASE_INSENSITIVE
Adding metadata columns
You can add several special columns to a table definition. If a column is present in the table definition, the ingestion process will populate the column as part of the ingestion. The current set of columns is:
| Column name | Contents |
|---|---|
| _METADATA_FILENAME | The file that the data came from. |
| _METADATA_ROWNUM | The row in the file that the data came from. |
| _METADATA_INGEST_DATE | The database date and time that the data was ingested. |
| _METADATA_JOB_ID | The DataOps.live job ID that ran the ingestion. |
| _METADATA_PIPELINE_ID | The DataOps.live pipeline ID that ran the ingestion. |
| _METADATA_BRANCH_NAME | The DataOps.live branch that ran the ingestion. |
Loading files using column matching
Load files from an external stage into the table with the match_by_column_name copy option. This involves performing a case-insensitive match between the column names in the files and those defined in the table. This option allows flexibility, as the column ordering in the files does not have to align with the column ordering in the table.
- Default Configuration
- Data Products Configuration
databases:
"{{ env.DATAOPS_DATABASE }}":
schemas:
SCHEMA1:
tables:
BEHAVIORAL_RISK_FACTOR_SURVEILLANCE_SYSTEM:
columns:
BREAKOUTCATEGORYID:
type: VARCHAR
BREAK_OUT:
type: VARCHAR
BREAK_OUT_CATEGORY:
type: VARCHAR
BREAKOUTID:
type: VARCHAR
CLASSID:
type: VARCHAR
CONFIDENCE_LIMIT_HIGH:
type: VARCHAR
DATASOURCE:
type: VARCHAR
DATA_VALUE_FOOTNOTE_SYMBOL:
type: VARCHAR
DATA_VALUE:
type: VARCHAR
DISPLAY_ORDER:
type: VARCHAR
GEOLOCATION:
type: VARCHAR
LOCATIONID:
type: VARCHAR
QUESTIONID:
type: VARCHAR
RESPONSEID:
type: VARCHAR
TOPICID:
type: VARCHAR
YEAR:
type: VARCHAR
orchestrators:
stage_ingestion:
stage: SOURCE_STAGE
file_format: PARQUET_FORMAT
PATH: parquet/Behavioral_Risk_Factor_Surveillance_System__BRFSS__Prevalence_Data__2011_to_present_.parquet
include_metadata: true | false
method: append | full_load
post_hook: sql|shell
truncate: true
copy:
force: true
match_by_column_name: CASE_INSENSITIVE
ASSET_OUTAGE:
comment: "assetOutage from eNAMS"
columns:
EN_NASAP_Circuit_Code__c:
type: VARCHAR(50)
EN_Record_Type_Name__c:
type: VARCHAR(50)
Name:
type: VARCHAR(50)
EN_Outage__c:
type: VARCHAR(50)
LastModifiedDate:
type: VARCHAR(50)
IsDeleted:
type: VARCHAR(50)
Id:
type: VARCHAR(50)
orchestrators:
stage_ingestion:
stage: SOURCE_STAGE
file_format: JSON_FORMAT
file_type: json
path: json/history_asset_outage.json
truncate: true
copy:
force: true
match_by_column_name: CASE_INSENSITIVE
- database:
name: "{{ env.DATAOPS_DATABASE }}"
- schema:
name: SCHEMA1
database: rel(database.{{ env.DATAOPS_DATABASE }})
- table:
name: BEHAVIORAL_RISK_FACTOR_SURVEILLANCE_SYSTEM
database: rel(database.{{ env.DATAOPS_DATABASE }})
schema: rel(schema.SCHEMA1)
columns:
BREAKOUTCATEGORYID:
type: VARCHAR
BREAK_OUT:
type: VARCHAR
BREAK_OUT_CATEGORY:
type: VARCHAR
BREAKOUTID:
type: VARCHAR
CLASSID:
type: VARCHAR
CONFIDENCE_LIMIT_HIGH:
type: VARCHAR
DATASOURCE:
type: VARCHAR
DATA_VALUE_FOOTNOTE_SYMBOL:
type: VARCHAR
DATA_VALUE:
type: VARCHAR
DISPLAY_ORDER:
type: VARCHAR
GEOLOCATION:
type: VARCHAR
LOCATIONID:
type: VARCHAR
QUESTIONID:
type: VARCHAR
RESPONSEID:
type: VARCHAR
TOPICID:
type: VARCHAR
YEAR:
type: VARCHAR
orchestrators:
stage_ingestion:
stage: SOURCE_STAGE
file_format: PARQUET_FORMAT
PATH: parquet/Behavioral_Risk_Factor_Surveillance_System__BRFSS__Prevalence_Data__2011_to_present_.parquet
include_metadata: true | false
method: append | full_load
post_hook: sql|shell
truncate: true
copy:
force: true
match_by_column_name: CASE_INSENSITIVE
- table:
name: ASSET_OUTAGE
database: rel(database.{{ env.DATAOPS_DATABASE }})
schema: rel(schema.SCHEMA1)
comment: "assetOutage from eNAMS"
columns:
EN_NASAP_Circuit_Code__c:
type: VARCHAR(50)
EN_Record_Type_Name__c:
type: VARCHAR(50)
Name:
type: VARCHAR(50)
EN_Outage__c:
type: VARCHAR(50)
LastModifiedDate:
type: VARCHAR(50)
IsDeleted:
type: VARCHAR(50)
Id:
type: VARCHAR(50)
orchestrators:
stage_ingestion:
stage: SOURCE_STAGE
file_format: JSON_FORMAT
file_type: json
path: json/history_asset_outage.json
truncate: true
copy:
force: true
match_by_column_name: CASE_INSENSITIVE
Loading using pattern matching
Load data from compressed CSV files located in any path within a table's stage using pattern matching, and then populate the table with the loaded data.
- Default Configuration
- Data Products Configuration
databases:
"{{ env.DATAOPS_DATABASE }}":
schemas:
SCHEMA1:
tables:
DISCHARGE_REPORT_BY_CODE_MS_2:
columns:
GEOGRAPHIC_UNIT:
type: TEXT
STUDENT_CATEGORY:
type: TEXT
CODE:
type: TEXT
CODE_TYPE:
type: TEXT
DESCRIPTION_OF_CODE:
type: TEXT
COUNT_OF_STUDENTS:
type: VARCHAR(255)
TOTAL_ENROLLED_STUDENTS:
type: NUMBER
orchestrators:
stage_ingestion:
stage: SOURCE_STAGE
file_format: CSV_FORMAT
PATH: csv
PATTERN: ".*/.*/.*[.]csv"
truncate: true
copy:
force: true
size_limit: 6000
purge: true
return_failed_length: true
enforce_length: true
truncatecolumns: false
load_uncertain_files: true
- database:
name: "{{ env.DATAOPS_DATABASE }}"
- schema:
name: SCHEMA1
database: rel(database.{{ env.DATAOPS_DATABASE }})
- table:
name: DISCHARGE_REPORT_BY_CODE_MS_2
database: rel(database.{{ env.DATAOPS_DATABASE }})
schema: rel(schema.SCHEMA1)
columns:
GEOGRAPHIC_UNIT:
type: TEXT
STUDENT_CATEGORY:
type: TEXT
CODE:
type: TEXT
CODE_TYPE:
type: TEXT
DESCRIPTION_OF_CODE:
type: TEXT
COUNT_OF_STUDENTS:
type: VARCHAR(255)
TOTAL_ENROLLED_STUDENTS:
type: NUMBER
orchestrators:
stage_ingestion:
stage: SOURCE_STAGE
file_format: CSV_FORMAT
PATH: csv
PATTERN: ".*/.*/.*[.]csv"
truncate: true
copy:
force: true
size_limit: 6000
purge: true
return_failed_length: true
enforce_length: true
truncatecolumns: false
load_uncertain_files: true
Where .\* is interpreted as “zero or more occurrences of any character.” The square brackets escape the period character (.) that precedes a file extension.
Loading JSON data into a VARIANT column
The following example loads JSON data into a table with a single column of type VARIANT.
{
"EN_NASAP_Circuit_Code__c": "Circuit123",
"EN_Outage__c": true,
"EN_RECORD_Type_Name__c": "TypeA",
"Id": "12345",
"IsDeleted": false,
"LastModifiedDate": "2023-10-24T14:30:00",
"Name": "AssetA"
}
- Default Configuration
- Data Products Configuration
databases:
"{{ env.DATAOPS_DATABASE }}":
schemas:
SCHEMA1:
tables:
ASSET_OUTAGE:
comment: "assetOutage from eNAMS"
columns:
JSON_DATA:
type: VARIANT
orchestrators:
stage_ingestion:
stage: external_data_stage
file_format: JSON_FORMAT
file_type: json
path: json/history_asset_outage.json
truncate: true
copy:
force: true
- database:
name: "{{ env.DATAOPS_DATABASE }}"
- schema:
name: SCHEMA1
database: rel(database.{{ env.DATAOPS_DATABASE }})
- table:
name: ASSET_OUTAGE
database: rel(database.{{ env.DATAOPS_DATABASE }})
schema: rel(schema.SCHEMA1)
comment: "assetOutage from eNAMS"
columns:
JSON_DATA:
type: VARIANT
orchestrators:
stage_ingestion:
stage: external_data_stage
file_format: JSON_FORMAT
file_type: json
path: json/history_asset_outage.json
truncate: true
copy:
force: true
Bulk loading from Amazon S3
Use the COPY INTO <table> command to transfer the data from the staged files into a table within a Snowflake database. While it's possible to load directly from the bucket, Snowflake advises creating an external stage that points to the bucket and utilizing the external stage instead.
Irrespective of the chosen method, this process mandates a currently active virtual warehouse for the session. Whether executing the command manually or within a script, the warehouse furnishes the computational resources necessary for the insertion of rows into the table.
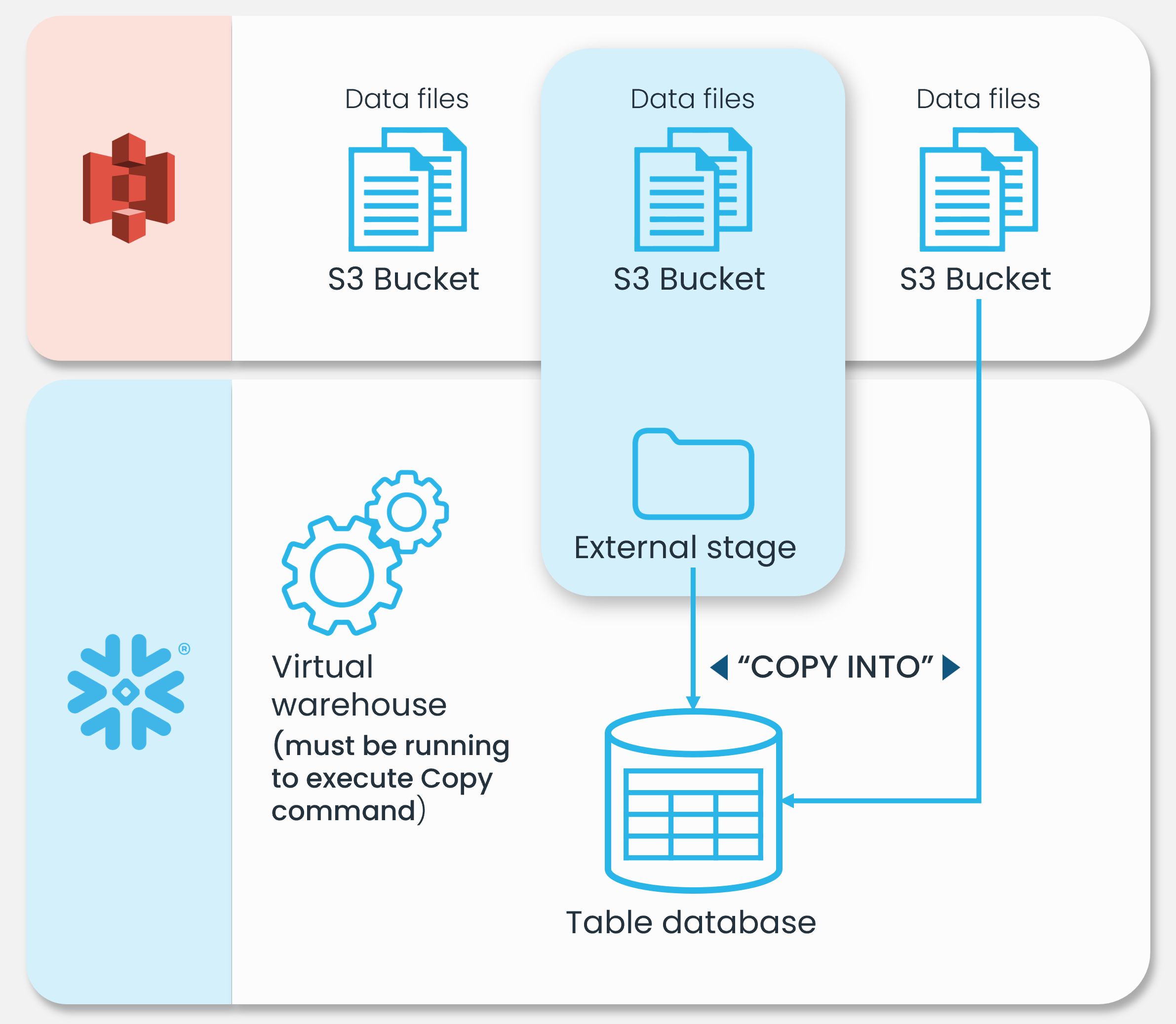
See the Snowflake documentation for more information.
Authentication
Key-pair authentication
The Stage Ingestion Orchestrator supports using key-pair authentication. To learn how to configure it, see key-pair authentication.
Auto-Generating sources from SOLE ingestion tables
Eliminate the need for manual addition of dbt sources by sharing table definitions between Snowflake Object Lifecycle Engine (SOLE) and Modelling and Transformation Engine (MATE). This streamlines onboarding for new data sources, reduces time to launch projects, and prevents duplicated efforts.
Sharing SOLE configuration files enables automatic metadata generation and transformation into ready-to-use MATE sources, providing a significant productivity advantage by eliminating the need for duplicate table definitions.
See the Auto-Generating Sources from SOLE Ingestion Tables documentation for more information.
For more information about generating sources for tables not managed by SOLE, see Generating Sources for Tables Managed Outside SOLE.