Forcing Ingestion in Development Branches
When modeling or transforming data with MATE or a third-party orchestrator, the zero-copy-clone of the production database provides actual, unchanged data for your dev or feature branch database. However, if the development work you want to do is modify data ingestion, just cloning is not helpful since the jobs that bring in new, modified data don't run by default.
Consider a typical ingestion job here for Stitch:
"My Stitch Job":
extends:
- .agent_tag
- .should_run_ingestion
stage: "My Stage"
image: $DATAOPS_STITCH_RUNNER_IMAGE
variables:
STITCH_ACTION: START
STITCH_SOURCE_ID: XXXX
STITCH_ACCESS_TOKEN: DATAOPS_VAULT(XXXX)
JOB_NAME: my_stitch_job # Not used inside the job, but used to match FORCE_INGESTION
script:
- /dataops
icon: ${STITCH_ICON}
Given the presence of the .should_run_ingestion base job, the default behavior in a development or feature branch is to skip ingestion and rely on the data provided by zero-copy-clone.
If you want to run ingestion in your dev or feature branch, then the variable FORCE_INGESTION can be used. When set as part of a pipeline execution run, the pipeline will run the job with the $JOB_NAME variable matching the FORCE_INGESTION variable.
You can use the execution variable FORCE_ALL_INGESTION to run all the ingestion jobs. See Pipeline Parameters for more information.
The following image shows a typical pipeline execution run that occurs on development or a feature branch but not on production or QA:
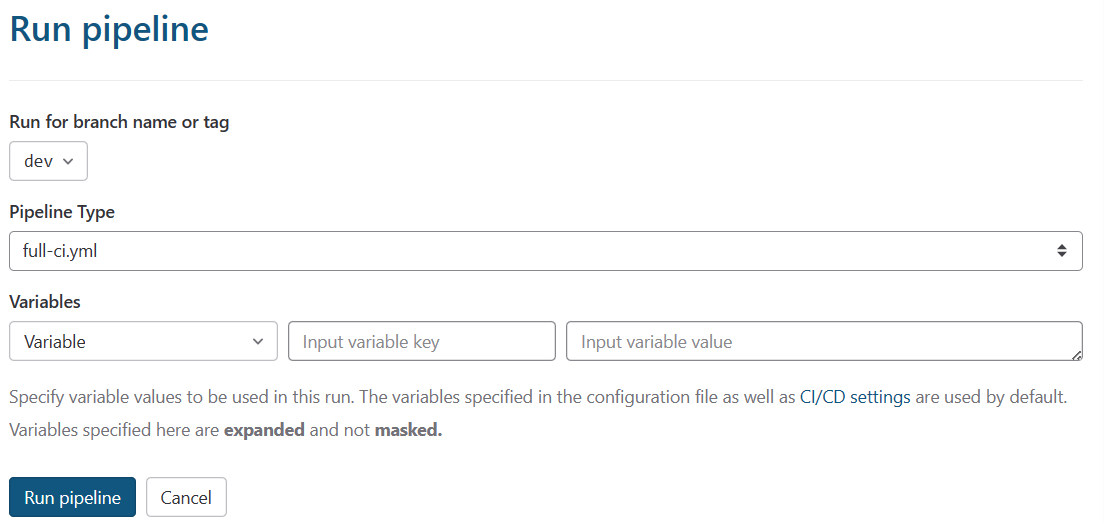
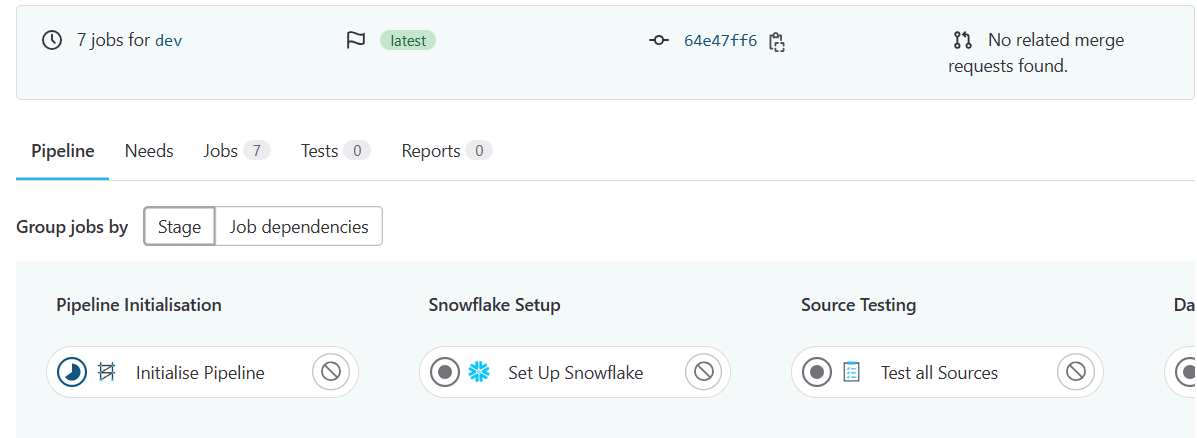
This run results in a pipeline where a job hasn't been selected, as follows:
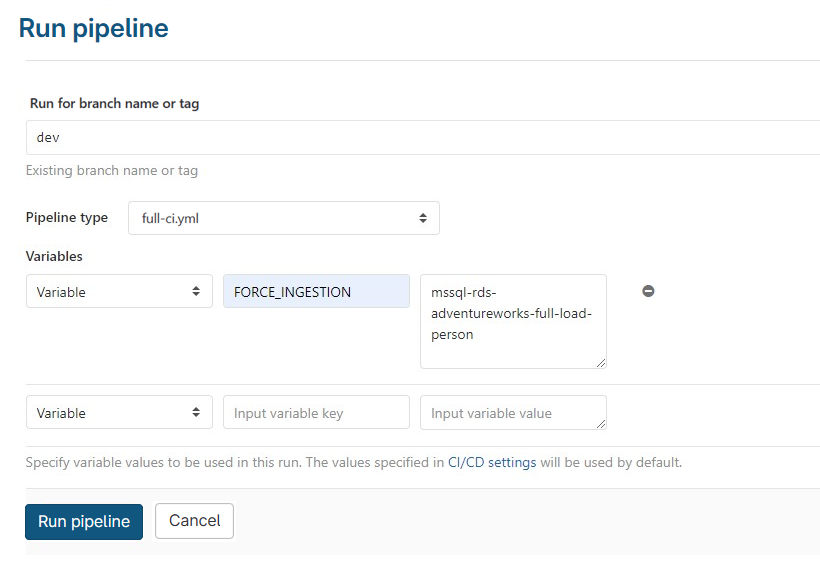
Setting the FORCE_INGESTION pipeline execution variable, as shown in the first image below, results in a pipeline where a job has been selected, as demonstrated in the second image:
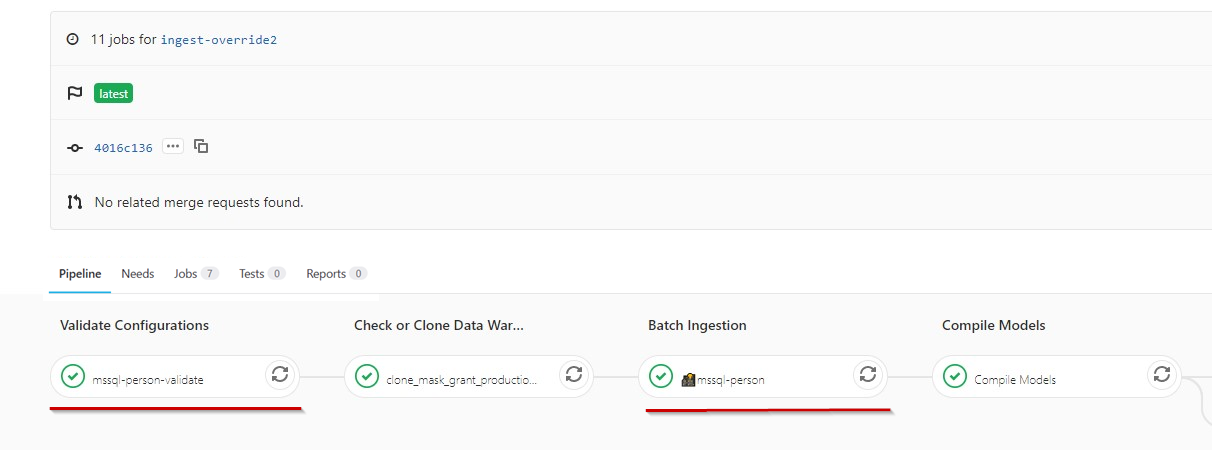
In summary, the ingestion job ran even though this was not a production or qa pipeline.