How to Create Incremental Models in MATE
Creating an incremental model is as simple as this example demonstrates. You have a source table that gets loaded once a day with data. From that, you create an incremental model that only processes "new" records loaded. This ensures a lighter model that only inserts new rows rather than recreating the entire table from scratch.
Setup
Let's say you have the following setup:
-
An ingestion table staging the daily load. Let's call this
SOURCE_TABLE
Set the table as a source:
dataops/modelling/sources/source_table.ymlversion: 2
sources:
- name: staging
tables:
- name: source_table
columns:
- name: name
- name: schema
- name: load_date
- name: load_count -
Set the incremental model
history_inc:dataops/modelling/models/history_inc.sql{{ config(
materialized='incremental'
) }}
select
name,
schema,
load_date,
load_count
from {{source('staging', 'source_table') }}
{% if is_incremental() %}
-- this filter will only be applied on an incremental run
where load_date > (select max(load_date) from {{ this }})
{% endif %}
A couple of things happen here:
-
You configure the model with
materialized = 'incremental'. The first run rebuilds the model entirely, and every subsequent run that does not have the--full-refreshoption set triggers theis_incremental()clause. -
You select to read the
SOURCE_TABLEfrom{{source('staging', 'source_table') }}. -
You have the
is_incremental()clause in Jinja{% if ... %}defining how to grab new rows. The condition what are new rows is:where load_date > (select max(load_date) from {{ this }}Where you say, "give me only rows with
load_datemore recent than what is currently the oldest row in this table".
If you want to read more about Jinja, head to our template rendering section.
Initial pipeline run
The initial pipeline run will produce the history_inc model:
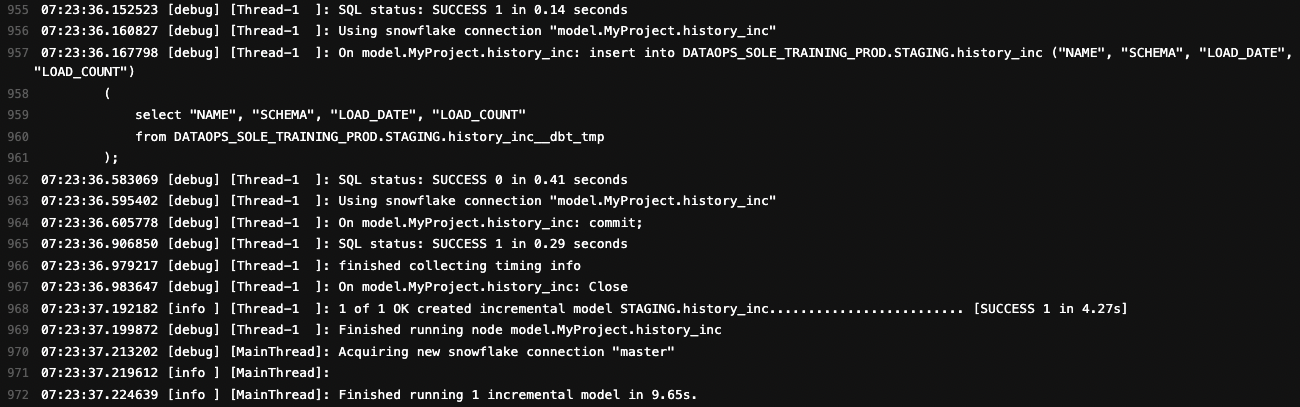
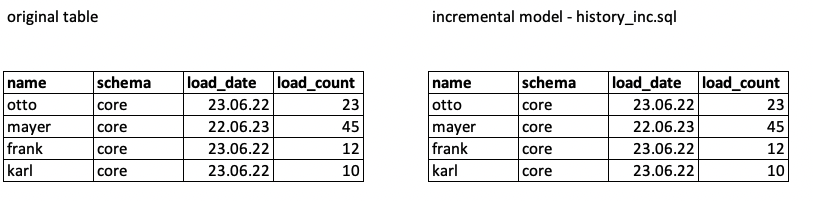
You can see that history_inc gets created. Checking the content, it is the same as the original table:
Subsequent pipeline runs
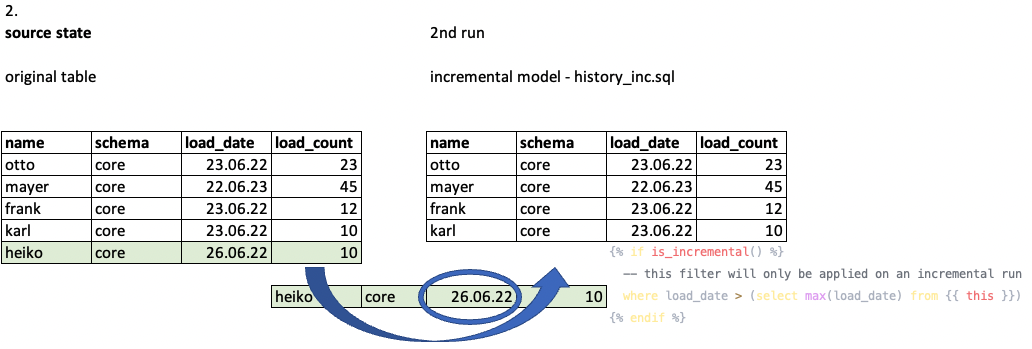
Now let's assume that ingestion happened and the original table had changed. It has an additional row that looks like row 5:

The subsequent MATE job run triggers the where clause and only selects the corresponding rows.

What happens is that the new row 5 gets added to the history_inc model:
Things to consider
It would be best if you were careful when using incremental runs. Defining where to put is_incremental() macro may significantly lighten your model and execution time, but one should take caution, e.g., when using window functions.