How to Prevent Concurrent Running of Pipelines
By default, DataOps runs pipelines in parallel. Pipelines run in parallel, and jobs of the same pipeline stage also run in parallel. Thus, you can effortlessly sequence jobs within a pipeline by adding them to different stages.
As a result, the question that we must ask and answer is how to sequence pipelines within different instances of the same pipeline or different pipelines.
This article answers this question by focusing on how to ensure that a new the pipeline does not start before the current pipeline run has been completed.
As an alternative to this approach, it is possible to configure subsequent pipeline instances to auto-abort if another is already running.
Adding a resource group
Resource groups are a means of limiting the concurrency of DataOps jobs. We will leverage them in this example by applying the same resource group to all jobs in a given pipeline.
The resulting workflow is as follows:
- A pipeline will start
- A given job in the pipeline will wait until the resource of the given name is free
- If the resource is not free, the pipeline will wait before executing the job until the resource is free
To achieve the desired result, we will introduce a new job,
No Parallel Run, at the Pipeline Initialisation stage to ensure that the
pipeline is blocked at its earliest possible stage.
In addition, we apply the resource group name sequential-pipeline to every
job.
No Parallel Run:
extends:
- .agent_tag
## Recommended values for resource group names
# Using the name of the job - limiting concurrency at the job level
# Using the name of the pipeline - limiting concurrency at the pipeline level
#
# the example uses the fixed name sequential-pipeline
resource_group: sequential-pipeline
stage: Pipeline Initialisation
script:
- echo 'sequential-pipeline starting'
icon: ${UTIL_ICON}
Long Ingestion Job:
extends:
- .agent_tag
# continue to use the fixed name sequential-pipeline to prevent the long-running
# ingest running concurrently
resource_group: sequential-pipeline
stage: Data Ingestion
script:
- echo 'Starting execution ...'
- sleep 60
- echo 'Completed execution ...'
icon: ${UTIL_ICON}
Clean Up:
extends:
- .agent_tag
# optional - continue to use the fixed name sequential-pipeline through all jobs
resource_group: sequential-pipeline
stage: Clean Up
script:
- echo 'sequential-pipeline done'
icon: ${UTIL_ICON}
To utilize these job definitions in a DataOps pipeline, like the following example, you can run two instances of the pipeline in parallel, and they will wait for each other.
include:
- /pipelines/includes/bootstrap.yml
# sync execution
- /pipelines/includes/local_includes/no_parallel_run.yml
Observing the two pipeline executions, you will see results similar to the following images:
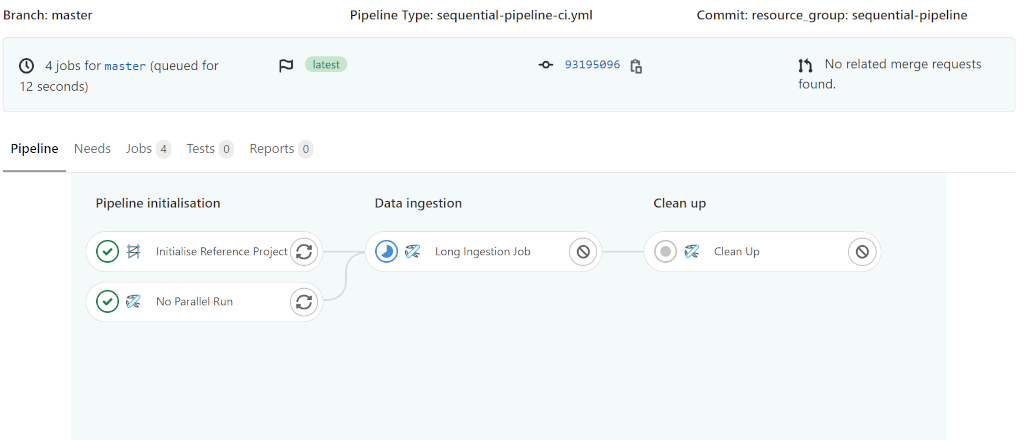
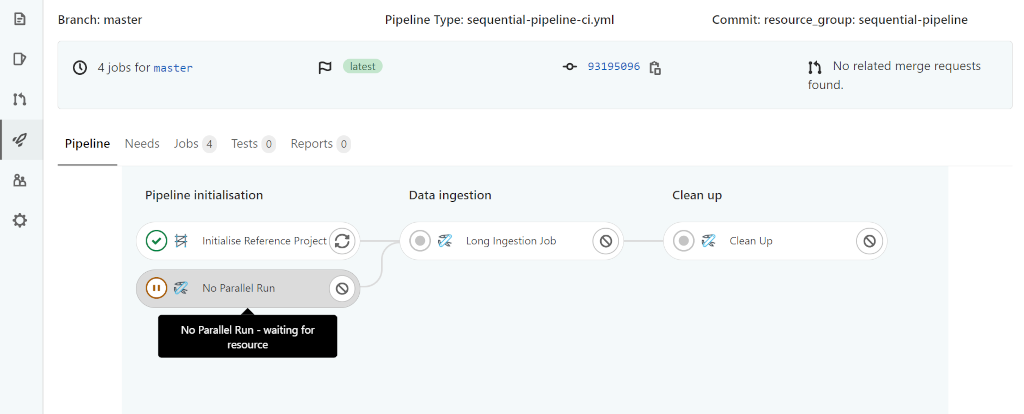
Considerations for jobs in a resource group.
When setting a resource group on a job that runs on a schedule, it's recommended to also place a timeout on that job that is a similar time to the interval of the schedule to prevent a build-up of jobs in the event of an unusually slow running job.
For example, let's say you have a job that usually takes 20 minutes in a resource group and runs in a schedule every 1 hour. If that job suddenly takes 90 minutes, a backlog of jobs will build up, worsening the situation. If unnoticed several days of jobs could build up even if the underlying issue causing the slow job has been fixed.
It very much depends on the job in question, but take time to consider what happens when a job in a resource group suddenly takes longer than expected.