Key Concepts
Now that we've covered the need for an engine like SOLE and looked at some use cases for Snowflake object lifecycle management in DataOps, this section describes the main concepts within SOLE.
Declarative configuration
As we established back in Why SOLE?, this is a declarative approach to object management and, as such, needs a declarative configuration.
SOLE uses a YAML-based configuration format that comprises several files, each specifying the objects
of a particular type (e.g., databases, warehouses, roles, users, etc.). These files sit together in the DataOps
project, located in a specific directory (dataops/snowflake).
Configuration files can include Jinja templating that will allow the inclusion of dynamic content during the pipeline run time. The files can include:
- Variables from the pipeline environment and the DataOps Vault
- Conditional statements to include parts of the configuration under certain conditions
- Control structures that can loop through a set of values, reducing the code footprint.
If configuration files include templated content, the filename will have .template., for example, databases.template.yml.
SOLE architecture
The DataOps Snowflake Object Lifecycle Engine is built on top of the popular infrastructure-as-code tool set Terraform, using the Chan-Zuckerberg Snowflake provider, along with a YAML-based configuration compiler, enhanced logging and reporting, and many other features.
When a SOLE job runs, configuration flows through the following system components in this order:
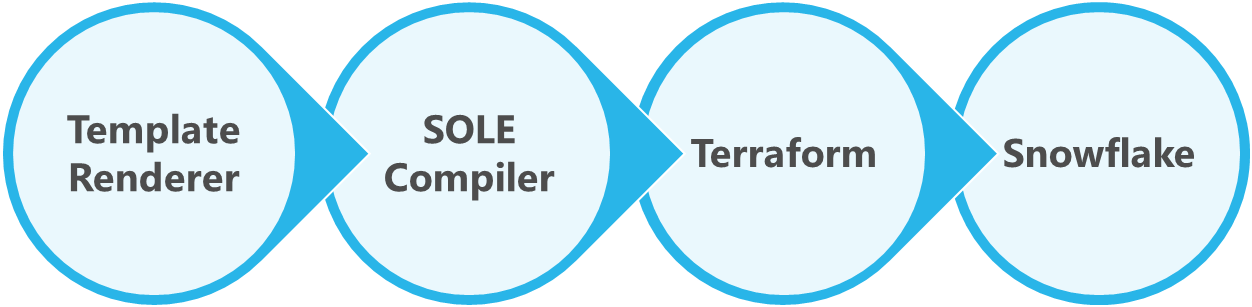
Template renderer
This component identifies files containing Jinja template content and renders them into static files. This operation resolves variables to their current values, optionally includes any conditional content, and expands out looped sections.
Each rendered file is saved under the original filename but without the .template modifier. The original template file is then deleted to avoid issues with the following stages.
SOLE compiler
Next, the rendered YAML files go through a compiler that converts the syntax from the SOLE YAML format into Terraform's JSON structures, adding computed properties and other settings as required by the object type.
This is done in four steps, SOLE's domains of operation:
- Account
- Database
- Database objects (schemas, tables, etc.)
- Grants
It is possible to export the Terraform configurations from a SOLE job using a DataOps artifact.
Terraform
Once the Terraform configurations are ready, they are applied to Snowflake in order. Terraform has its compile, plan, and apply stages, but that is beyond the scope of this guide.
As part of this process stage, Snowflake configuration is imported to compute the needed changes. And if the SOLE configuration includes a database clone (such as in a feature branch), there is an additional import from the newly-cloned database to detect its contents.
Snowflake
The SOLE configuration is fully applied to the Snowflake account, with only the minimum necessary changes to update existing objects. The job summarizes the number of additions, changes, and deletions that were applied to each domain of operation, e.g.:
| Resource type | Action | Objects Added | Objects Modified | Objects Deleted |
----------------------------------------------------------------------------------------------------------
| ACCOUNT_LEVEL | PLAN | 5 | 1 | 0 |
| ACCOUNT_LEVEL | APPLY | 5 | 1 | 0 |
| DATABASE | PLAN | 0 | 0 | 0 |
| DATABASE | APPLY | 0 | 0 | 0 |
| DATABASE_LEVEL | PLAN | 0 | 0 | 0 |
| DATABASE_LEVEL | APPLY | 0 | 0 | 0 |
| GRANT | PLAN | 0 | 8 | 3 |
| GRANT | APPLY | 0 | 8 | 3 |
Defining objects
Objects are defined in the YAML configuration files as mentioned above. Here is a simple example of a warehouse object in SOLE:
warehouses:
TRANSFORMATION:
comment: Warehouse for Transformation operations
warehouse_size: MEDIUM
auto_suspend: 40
auto_resume: true
grants:
USAGE:
- WRITER
- READER
The above configuration creates and maintains a medium warehouse in Snowflake with the specified suspend/resume settings and access to be used by the two roles.
Namespacing
In the example configuration above, the warehouse name is specified as TRANSFORMATION, but that's not the full name that will end up in Snowflake, as SOLE can apply a namespacing prefix and suffix to all account-level objects.
Namespacing is vital so objects can coexist across different DataOps projects and environments. SOLE applies a prefix, a suffix, or both to object names to achieve this.
Project prefix
In all DataOps projects, you can define a value for the variable DATAOPS_PREFIX at pipelines/includes/config/variables.yml. This variable specifies the primary identifier for the project. The default value is usually DATAOPS, but you can change it in projects.
Supported characters in DATAOPS_PREFIX are letters (A-Z), decimal digits ( 0-9), and an underscore (_).
This prefix allows multiple projects to coexist within the same Snowflake account, or at least identifies account-level objects as being managed by DataOps.
Environment suffix
When a pipeline is run, the environment is determined from the current branch: the main branch is the PROD
environment, dev is DEV, etc. Feature branches (e.g. any branch that is not main, qa or dev)
will have a generated environment name of the form FB_BRANCHNAME.
This suffix allows each environment to have its own set of Snowflake objects, without the risk of name collisions.
Resultant naming
So, from the warehouse example above, if you set the project's DATAOPS_PREFIX to DATAOPS and run a pipeline in the dev branch, the warehouse name will be DATAOPS_TRANSFORMATION_DEV.
Supported characters in DATAOPS_PREFIX are letters (A-Z), decimal digits ( 0-9), and an underscore (_).
If you merge the dev code into the main branch and rerun the pipeline, the new warehouse name will be DATAOPS_TRANSFORMATION_PROD.
Notes on namespacing
When referring to another object in an object's configuration, for example, the roles READER and
WRITER in the code above, always use the base, non-namespaced name. The SOLE compiler sorts
out all the resultant names for you. The exception here is when referring to an externally-managed
object - see below for more on that.
It is possible to disable namespacing, limiting it to prefix-only, or suffix-only, or turn it off altogether. This will be covered later.
Disabling namespacing can impact your production environment and cause conflicts between projects. It's there for a reason, so please ensure you understand it fully.
Setting namespacing to none or prefix prevents the deletion of the object. Please refer to Environment-Specific Snowflake Objects.
To manage the object's lifecycle but not its prefix and suffix, you can set namespacing to external.
Roles and grants
As the primary use case for SOLE, managing roles and grants is a core functionality and should feature in all DataOps projects. The standard SOLE configuration has a file roles.yml you can extend to include all the roles your project needs to define and how you assign them to each other and users.
Each object has a grants block (see the example above) that then specifies which roles can enjoy which privileges on that object.
Externally-managed objects
DataOps will not manage every single object in your Snowflake account. Even if it's doing most things, you will still have several other entities, particularly the built-in roles, user accounts, sample data database, etc.
Here comes SOLE manage_mode that lets you define how to interact with objects outside SOLE control. For most objects configured in SOLE, the default manage_mode is set to all, allowing SOLE full control over the objects, but it is also possible to declare objects as externally managed.
For example, you may want to grant MY_ROLE to the built-in SYSADMIN role to maintain the role hierarchy:
roles:
MY_ROLE:
comment: main role for my project
roles:
- SYSADMIN
SYSADMIN:
manage_mode: none
namespacing: none
Read more on manage_mode here.