SOLE Generator
The SOLE Generator is a CLI (Command-line Interface) tool that helps you generate a YAML configuration for SOLE objects from existing DDL statements. This tool is handy when you want to start managing your existing Snowflake databases through the data product platform. Instead of manually creating your database.template.yml file, you can do that using this tool.

Below is a list of all the objects that are currently supported:
Prerequisites
First, install the CLI as part of the DataOps CLI package.
Before using the tool, you need to have the Snowflake DDL statements for the objects for which you want to generate the configuration. To get that, you can run the GET_DDL command in your Snowflake account. For example:
select get_ddl('DATABASE', 'SALES_RECORD', true);
The output of the GET_DDL command is the actual SQL CREATE statement of the specific SOLE object, including its children's objects. In the example above, the output will include the CREATE statements for all objects that belong to the SALES_RECORD database (schemas, tables, procedures and so on).
For more accurate parsing, enable the use_fully_qualified_names_for_recreated_objects property of the GET_DDL command.
Usage
The SOLE Generator comes as part of the DataOps CLI tool. If you haven't installed it already, you can do so by following the steps explained in DataOps CLI.
The available options for the SOLE Generator CLI are listed in the image below:
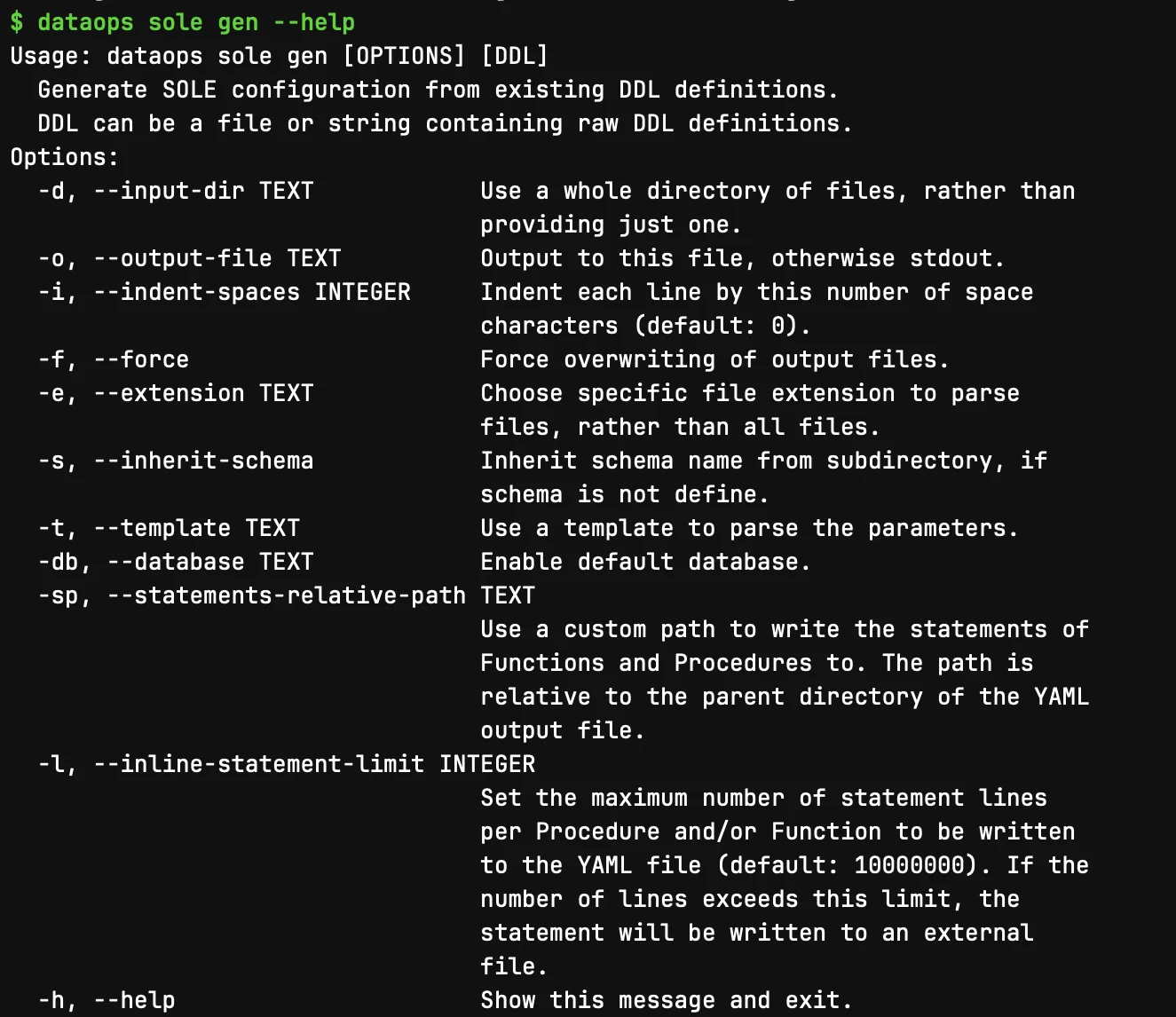
If you are using SOLE, you can check them out at any time by running the following command in your terminal window:
dataops sole gen --help
To do the same for SOLE for Data Products, use:
dataops sole-dp gen --help
The dataops solegen command is scheduled to be deprecated shortly. Kindly transition to using dataops sole gen as the alternative.
Once you have the toolset, you can start generating the YAML configuration for your SOLE objects.
Generating SOLE configuration from a raw DDL statement
The SOLE Generator lets you generate SOLE configuration from raw SQL CREATE queries. You can do that by passing the SQL
query as an argument either to the dataops sole gen or dataops sole-dp gen command, depending on the version of SOLE
that you are using. For example:
- Classic Configuration
- Data Products Configuration
dataops sole gen "create schema SALES_RECORD.SALES comment='This is a test DataOps.live schema.';"
dataops sole-dp gen "create schema SALES_RECORD.SALES comment='This is a test DataOps.live schema.';"
The YAML configuration generated by the SOLE Generator for the example above would be:
- Classic Configuration
- Data Products Configuration
databases:
SALES_RECORD:
schemas:
SALES:
comment: This is a test DataOps.live schema.
manage_mode: all
- schema:
name: SALES
database: rel(database.SALES_RECORD)
comment: This is a test DataOps.live schema.
manage_mode: all
Generating SOLE configuration from DDL files
Parsing raw DDL statements is useful when you want to generate the configuration for a single object. But, if you want to parse multiple objects simultaneously, you can pass a DDL file, or even a whole directory to the SOLE Generator.
Generate configuration from a single DDL file
To parse a single DDL file, use:
- Classic Configuration
- Data Products Configuration
dataops sole gen /path/to/file/database.sql
dataops sole-dp gen /path/to/file/database.sql
If the content of the DDL file for your database is:
create or replace database SALES_RECORD DATA_RETENTION_TIME_IN_DAYS=5;
create or replace schema SALES_RECORD.SALES;
create or replace TABLE SALES_RECORD.SALES.CUSTOMER (
CUSTOMERID NUMBER(38,0) NOT NULL,
ACCOUNTNUMBER VARCHAR(16777216),
FULLNAME VARCHAR(16777216),
MODIFIEDDATE TIMESTAMP_NTZ(9) NOT NULL
);
create or replace TABLE SALES_RECORD.SALES.PRODUCT (
PRODUCTID NUMBER(38,0) NOT NULL,
DESCRIPTION VARCHAR(100),
UNITPRICE NUMBER(24,2) NOT NULL,
MODIFIEDDATE TIMESTAMP_NTZ(9) NOT NULL
);
CREATE TASK SALES_RECORD.SALES.mytask1 AFTER db2.schema2.mytask2 as SELECT CURRENT_TIMESTAMP;
CREATE OR REPLACE FILE FORMAT SALES_RECORD.SALES.my_csv_format
TYPE = CSV
FIELD_DELIMITER = '|'
SKIP_HEADER = 1
NULL_IF = ('NULL', 'null')
EMPTY_FIELD_AS_NULL = true
COMPRESSION = gzip;
create or replace tag SALES_RECORD.SALES.DATA_DOMAIN_TAG ALLOWED_VALUES 'Sensitive', 'Highly Sensitive' comment= 'data domain tag';
create or replace sequence SALES_RECORD.SALES.SEQUENCE_1 increment by 1 comment= 'Object sequence';
create or replace STREAM SALES_RECORD.SALES.STREAM_1 on table DATABASE_3.SCHEMA_3.TABLE_2 append_only = false comment = 'Object stream' insert_only = false show_initial_rows = false;
create or replace row access policy SALES_RECORD.SALES.rap_sales_manager_regions_1 as (sales_region varchar) returns boolean ->
'sales_executive_role' = current_role()
or exists (
select 1 from salesmanagerregions
where sales_manager = current_role()
and region = sales_region
)
;
Its corresponding YAML configuration generated by the tool would be:
- Classic Configuration
- Data Products Configuration
databases:
SALES_RECORD:
data_retention_time_in_days: "5"
schemas:
SALES:
tables:
CUSTOMER:
columns:
CUSTOMERID:
type: NUMBER(38,0)
nullable: false
ACCOUNTNUMBER:
type: VARCHAR(16777216)
nullable: true
FULLNAME:
type: VARCHAR(16777216)
nullable: true
MODIFIEDDATE:
type: TIMESTAMP_NTZ(9)
nullable: false
change_tracking: false
manage_mode: all
PRODUCT:
columns:
PRODUCTID:
type: NUMBER(38,0)
nullable: false
DESCRIPTION:
type: VARCHAR(100)
nullable: true
UNITPRICE:
type: NUMBER(24,2)
nullable: false
MODIFIEDDATE:
type: TIMESTAMP_NTZ(9)
nullable: false
change_tracking: false
manage_mode: all
tasks:
mytask1:
sql_statement: SELECT CURRENT_TIMESTAMP;
after:
database: db2
schema: schema2
name: mytask2
file_formats:
my_csv_format:
format_type: CSV
manage_mode: all
compression: gzip
empty_field_as_null: true
field_delimiter: "|"
null_if:
- "NULL"
- "null"
skip_header: 1
tags:
DATA_DOMAIN_TAG:
comment: data domain tag
allowed_values:
- Sensitive
- Highly Sensitive
sequences:
SEQUENCE_1:
comment: Object sequence
increment: 1
streams:
STREAM_1:
comment: Object stream
append_only: false
insert_only: false
show_initial_rows: false
on_table:
database: DATABASE_3
schema: SCHEMA_3
name: TABLE_2
manage_mode: all
row_access_policies:
rap_sales_manager_regions_1:
signature:
sales_region: varchar
row_access_expression: |-
'sales_executive_role' = current_role()
OR EXISTS (
SELECT 1
FROM salesmanagerregions
WHERE sales_manager = current_role()
AND region = sales_region
)
manage_mode: all
is_managed: false
is_transient: false
manage_mode: all
namespacing: both
manage_mode: all
- database:
name: SALES_RECORD
data_retention_time_in_days: 5
namespacing: both
manage_mode: all
- schema:
name: SALES
database: rel(database.SALES_RECORD)
is_managed: false
is_transient: false
manage_mode: all
- table:
name: CUSTOMER
database: rel(database.SALES_RECORD)
schema: rel(schema.SALES)
columns:
CUSTOMERID:
type: NUMBER(38,0)
nullable: false
ACCOUNTNUMBER:
type: VARCHAR(16777216)
nullable: true
FULLNAME:
type: VARCHAR(16777216)
nullable: true
MODIFIEDDATE:
type: TIMESTAMP_NTZ(9)
nullable: false
change_tracking: false
manage_mode: all
- table:
name: PRODUCT
database: rel(database.SALES_RECORD)
schema: rel(schema.SALES)
columns:
PRODUCTID:
type: NUMBER(38,0)
nullable: false
DESCRIPTION:
type: VARCHAR(100)
nullable: true
UNITPRICE:
type: NUMBER(24,2)
nullable: false
MODIFIEDDATE:
type: TIMESTAMP_NTZ(9)
nullable: false
change_tracking: false
manage_mode: all
- task:
name: mytask1
database: rel(database.SALES_RECORD)
schema: rel(schema.SALES)
sql_statement: SELECT CURRENT_TIMESTAMP
after:
database: db2
schema: schema2
name: mytask2
manage_mode: all
- file_format:
name: my_csv_format
database: rel(database.SALES_RECORD)
schema: rel(schema.SALES)
format_type: CSV
manage_mode: all
compression: gzip
empty_field_as_null: true
field_delimiter: "|"
null_if:
- "NULL"
- "null"
skip_header: 1
- tag:
name: DATA_DOMAIN_TAG
database: rel(database.SALES_RECORD)
schema: rel(schema.SALES)
comment: data domain tag
allowed_values:
- Sensitive
- Highly Sensitive
manage_mode: all
- sequence:
name: SEQUENCE_1
database: rel(database.SALES_RECORD)
schema: rel(schema.SALES)
comment: Object sequence
increment: 1
manage_mode: all
- stream:
name: STREAM_1
database: rel(database.SALES_RECORD)
schema: rel(schema.SALES)
comment: Object stream
append_only: false
insert_only: false
show_initial_rows: false
on_table:
database: DATABASE_3
schema: SCHEMA_3
table: TABLE_2
manage_mode: all
- row_access_policy:
name: rap_sales_manager_regions_1
database: rel(database.SALES_RECORD)
schema: rel(schema.SALES)
signature:
sales_region: varchar
row_access_expression: |-
'sales_executive_role' = current_role()
OR EXISTS (
SELECT 1
FROM salesmanagerregions
WHERE sales_manager = current_role()
AND region = sales_region
)
manage_mode: all
Generate configuration from a directory
To parse a whole directory containing multiple DDL files, run:
- Classic Configuration
- Data Products Configuration
dataops sole gen -d /path/to/directory
dataops sole-dp gen -d /path/to/directory
This command merges the SOLE configuration of all DDL files from the input directory into a single output.
If the input directory contains subdirectories, the files from those subdirectories will be parsed too.
Additionally, you can:
-
Use the
-eoption to specify the file format that needs parsing. To filter*.sqlfiles only, run:- Classic Configuration
- Data Products Configuration
dataops sole gen -d /path/to/directory -e .sqldataops sole-dp gen -d /path/to/directory -e .sql -
Use the
-soption to inherit the schema name from the subdirectory if the schema isn't defined.If a SQL file is located in a subdirectory and the object name does not include the schema, then the subdirectory name would be used as the schema name.
If a SQL file is located in a subdirectory and the object name already includes the schema, then the
--inherit-schema(-s) flag is ignored.- Classic Configuration
- Data Products Configuration
dataops sole gen -d /path/to/directory -sdataops sole gen-dp -d /path/to/directory -sFor example, if we have a folder structure as follows:
snowflake/
|- tables/
| |- schema1/
| | |- TABLE1.sql
| | |- TABLE2.sql
| |- schema2/
| | |- TABLE3.sql
| | |- TABLE4.sqlYou can run the SOLE Generator with the
-soption as follows:- Classic Configuration
- Data Products Configuration
dataops sole gen -d /path/to/directory -s > tables.yamldataops sole-dp gen -d /path/to/directory -s > tables.yamlThe resulting
tables.yamlfile will contain table definitions that specify the schema based on the subdirectory name:- Classic Configuration
- Data Products Configuration
databases:
"{{ env.DATAOPS_DATABASE }}":
schemas:
schema_1:
tables:
TABLE1:
# contents of TABLE1.sql
TABLE2:
# contents of TABLE2.sql
schema_2:
tables:
TABLE3:
# contents of TABLE3.sql
TABLE4:
# contents of TABLE4.sql- table:
name: TABLE1
database: rel(database.{{ env.DATAOPS_DATABASE }})
schema: rel(schema.schema_1)
# contents of TABLE1.sql
- table:
name: TABLE2
database: rel(database.{{ env.DATAOPS_DATABASE }})
schema: rel(schema.schema_1)
# contents of TABLE2.sql
- table:
name: TABLE3
database: rel(database.{{ env.DATAOPS_DATABASE }})
schema: rel(schema.schema_2)
# contents of TABLE3.sql
- table:
name: TABLE4
database: rel(database.{{ env.DATAOPS_DATABASE }})
schema: rel(schema.schema_2)
# contents of TABLE4.sql
Using templates to define default parameter values
The SOLE Generator generates YAML configuration files from DDL statements that are subsequently run in SOLE to manage existing Snowflake databases through the data product platform. Sometimes DDLs don't contain all the needed parameters. In such a case, default values are used, but users need to change them manually in all the generated YAML files if they want to use different values.
Using templates with SOLE Generator simplifies customizing parameter values not included initially in DDLs while generating the configuration YAML files for the database objects. You can create templates containing your desired DataOps parameter values and store them on your local machines. Using the template with the dataops sole gen command will merge the template with the incoming DDLs and use the parameters specified in the template files as defaults when generating the YAML files.
Create a template
To create a template, you must create a YAML/JSON file or Python dictionary specifying the parameters and their default values. For example, if you want to set the manage_mode of a schema to none, you can either:
- Create a YAML File
- Create a JSON File
- Use a Python Dictionary
databases:
MYDATABASE:
schemas:
MYSCHEMA:
manage_mode: none
{
"databases": {
"MYDATABASE": {
"schemas": {
"MYSCHEMA": {
"manage_mode": "none"
}
}
}
}
}
{
"databases": {
"MYDATABASE": {
"schemas": {
"MYSCHEMA": {
"manage_mode": "none"
}
}
}
}
}
Each template above represents a possible way of setting the manage_mode of the MYSCHEMA schema to none.
See Use wildcards in templates for information about applying the same configuration to all schemas.
Use a template
Once you have created a template, you can use it with the dataops sole gen command by specifying the -t or --template option followed by the path to the template file.
For example, to use the templates mentioned above, you can run either of the following commands depending on the format of your template:
- Use a YAML Template File
- Use a JSON Template File
- Use a Python Dictionary Template
dataops sole gen -t /path/to/mytemplate.yaml "CREATE SCHEMA MYDATABASE.MYSCHEMA"
dataops sole gen -t /path/to/mytemplate.json "CREATE SCHEMA MYDATABASE.MYSCHEMA"
dataops sole gen -t '{"databases": {"MYDATABASE": {"schemas": {"MYSCHEMA": {"manage_mode": "none"}}}}}' "CREATE SCHEMA MYDATABASE.MYSCHEMA"
Any of the above commands will generate the YAML output, including the parameters specified in the template. For example:
databases:
MYDATABASE:
schemas:
MYSCHEMA:
...
manage_mode: none
Use wildcards in templates
You can also use wildcards in templates to specify default values for multiple objects of the same type. For example, to set the manage_mode of all schemas to none, you can create a template choosing one of the following formats:
- YAML Template
- JSON Template
- Python Dictionary Template
databases:
MYDATABASE:
schemas:
"*":
manage_mode: none
{
"databases": {
"MYDATABASE": {
"schemas": {
"*": {
"manage_mode": "none"
}
}
}
}
}
{
"databases": {
"MYDATABASE": {
"schemas": {
"*": {
"manage_mode": "none"
}
}
}
}
}
Each template above represents a possible way of setting the manage_mode of all schemas to none using the wildcard * in the name field. You can then use any of these templates with the dataops sole gen command to generate configuration files for all schemas.
To set the manage_mode of all schemas and tables to none, you can create a template choosing one of the following formats:
- YAML Template
- JSON Template
- Python Dictionary Template
databases:
MYDATABASE:
schemas:
"*":
manage_mode: none
tables:
"*":
manage_mode: none
{
"databases": {
"MYDATABASE": {
"schemas": {
"*": {
"manage_mode": "none",
"tables": {
"*": {
"manage_mode": "none"
}
}
}
}
}
}
}
{
"databases": {
"MYDATABASE": {
"schemas": {
"*": {
"manage_mode": "none",
"tables": {
"*": {
"manage_mode": "none"
}
}
}
}
}
}
}
To set default values for various configuration parameters related to the SALES_RECORD database, its SALES schema, and its tables, you can create a template choosing one of the following formats:
- YAML Template
- JSON Template
- Python Dictionary Template
databases:
SALES_RECORD:
data_retention_time_in_days: "6"
comment: database comment
namespacing: prefix
manage_mode: none
schemas:
SALES:
tables:
"*":
comment: table comment
change_tracking: true
manage_mode: none
grants:
USAGE:
- ROLE_1
- SYSADMIN:
with_grant_option: true
MODIFY:
- ROLE_1
- ROLE_2
manage_mode: none
comment: schema comment
{
"databases": {
"SALES_RECORD": {
"data_retention_time_in_days": "6",
"comment": "database comment",
"namespacing": "prefix",
"manage_mode": "none",
"schemas": {
"SALES": {
"tables": {
"*": {
"comment": "table comment",
"change_tracking": "true",
"manage_mode": "none",
"grants": {
"USAGE": [
"ROLE_1",
{ "SYSADMIN": { "with_grant_option": "true" } }
],
"MODIFY": ["ROLE_1", "ROLE_2"]
}
}
},
"manage_mode": "none",
"comment": "schema comment"
}
}
}
}
}
{
"databases": {
"SALES_RECORD": {
"data_retention_time_in_days": "6",
"comment": "database comment",
"namespacing": "prefix",
"manage_mode": "none",
"schemas": {
"SALES": {
"tables": {
"*": {
"comment": "table comment",
"change_tracking": "true",
"manage_mode": "none",
"grants": {
"USAGE": [
"ROLE_1",
{"SYSADMIN": {"with_grant_option": "true"}}
],
"MODIFY": ["ROLE_1", "ROLE_2"]
}
}
},
"manage_mode": "none",
"comment": "schema comment"
}
}
}
}
}
To use any of the above templates, you can run either of the following commands depending on the format of your template:
- YAML Template
- JSON Template
- Python Dictionary Template
dataops sole gen -t /path/to/template.yaml /path/to/file/database.sql
dataops sole gen -t /path/to/template.json /path/to/file/database.sql
dataops sole gen -t '{
"databases": {
"SALES_RECORD": {
"data_retention_time_in_days": "6",
"comment": "database comment",
"namespacing": "prefix",
"manage_mode": "none",
"schemas": {
"SALES": {
"tables": {
"*": {
"comment": "table comment",
"change_tracking": "true",
"manage_mode": "none",
"grants": {
"USAGE": [
"ROLE_1",
{"SYSADMIN": {"with_grant_option": "true"}}
],
"MODIFY": ["ROLE_1", "ROLE_2"]
}
}
},
"manage_mode": "none",
"comment": "schema comment"
}
}
}
}
}' /path/to/file/database.sql
Any of the above commands will generate the YAML output, including the parameters specified in the template. For example:
databases:
SALES_RECORD:
data_retention_time_in_days: "6"
schemas:
SALES:
tables:
CUSTOMER:
columns:
CUSTOMERID:
type: NUMBER(38,0)
nullable: false
ACCOUNTNUMBER:
type: VARCHAR(16777216)
nullable: true
FULLNAME:
type: VARCHAR(16777216)
nullable: true
MODIFIEDDATE:
type: TIMESTAMP_NTZ(9)
nullable: false
change_tracking: true
manage_mode: none
comment: table comment
grants:
USAGE:
- ROLE_1
- SYSADMIN:
with_grant_option: true
MODIFY:
- ROLE_1
- ROLE_2
PRODUCT:
columns:
PRODUCTID:
type: NUMBER(38,0)
nullable: false
DESCRIPTION:
type: VARCHAR(100)
nullable: true
UNITPRICE:
type: NUMBER(24,2)
nullable: false
MODIFIEDDATE:
type: TIMESTAMP_NTZ(9)
nullable: false
change_tracking: true
manage_mode: none
comment: table comment
grants:
USAGE:
- ROLE_1
- SYSADMIN:
with_grant_option: true
MODIFY:
- ROLE_1
- ROLE_2
is_managed: false
is_transient: false
manage_mode: none
comment: schema comment
namespacing: prefix
manage_mode: none
comment: database comment
Overwriting the default database
The SOLE Generator retrieves the database name for each object from its fully qualified name if such name is provided in
the DDL query. If a fully qualified name is absent in the DDL query, the SOLE Generator defaults to setting the database name to
{{ env.DATAOPS_DATABASE }}.
To overwrite the default database name, use the --database or -db option of the dataops sole gen command:
dataops sole gen "create schema SALES comment='This is a test DataOps.live schema.';" -db MY_DATABASE
The YAML configuration generated by the SOLE Generator for the example above would be:
databases:
MY_DATABASE:
schemas:
SALES:
comment: This is a test DataOps.live schema.
Managing your output files
By default, the SOLE Generator outputs the YAML configuration to the standard output (in the Terminal window). To write the configuration into a YAML file, you can use the -o option of the dataops sole gen command:
- Classic Configuration
- Data Products Configuration
dataops sole gen /path/to/input/file/database.sql -o /path/to/output/file/database.yml
dataops sole-dp gen /path/to/input/file/database.sql -o /path/to/output/file/database.yml
If the output file already exists, you can overwrite it by adding the force flag:
- Classic Configuration
- Data Products Configuration
dataops sole gen /path/to/input/file/database.sql -o /path/to/output/file/database.yml -f
dataops sole-dp gen /path/to/input/file/database.sql -o /path/to/output/file/database.yml -f
Writing the statements of procedures or functions as separate files
When generating the SOLE configuration for
procedures or functions,
the statement of each of them is stored directly in the generated YAML file. However, it is possible to store the
statements in external files. To do that, you must have both the --output-file (-o) and --inline-statement-limit (-l)
arguments set. The --inline-statement-limit argument lets you specify the maximum number of lines the statement
can have to be stored directly into the YAML file. A statement is automatically stored in an external file if it exceeds that
limit. For example:
- Classic Configuration
- Data Products Configuration
dataops sole gen $INPUT_DDL_FILE -o /path/to/output/procedure.yml --inline-statement-limit 10
dataops sole-dp gen $INPUT_DDL_FILE -o /path/to/output/procedure.yml --inline-statement-limit 10
The statements are stored in the same directory as the YAML file by default. You can overwrite the default location using
the --statements-relative-path option. This way, the statement files will be created in the specified directory relative
to the YAML file. For example, if you set the value of -o to /path/to/output and --statements-relative-path to
procedures/test_procedure, the statements will be stored in the /path/to/output/procedures/test_procedure directory.
For example:
- Classic Configuration
- Data Products Configuration
dataops sole gen $INPUT_DDL_FILE -o /path/to/output/procedure.yml -l 10 \
--statements-relative-path procedures/test_procedure
dataops sole-dp gen $INPUT_DDL_FILE -o /path/to/output/procedure.yml -l 10 \
--statements-relative-path procedures/test_procedure
For each procedure or function
that has a statement longer than 10 lines, the SOLE Generator will create a separate file containing only the statement
of the corresponding object and link that file in the YAML configuration using the !dataops.include directive. If a
statement is shorter than 10 lines, it will be stored directly in the YAML configuration.
Writing the statements into the YAML output directly is more error prone and may increase the size of the file significantly. It is recommended to use inline statements only for small procedures or functions.