Soda Orchestrator
Enterprise
| Image | $DATAOPS_SODA_RUNNER_IMAGE |
|---|---|
| Feature Status | PubPrev |
The Soda orchestrator enables Soda users to execute automated testing as part of a DataOps pipeline, supporting operations provided by Soda SQL (Soda's open-source product). The test results are reported back to the user through the DataOps.live data product platform or Soda Cloud. The DataOps pipeline pushes the results to Soda Cloud, adding significant additional value to the resulting output - see Soda Cloud.
The Soda Orchestrator requires two inputs:
- A warehouse file
- A set of scan files
When the /dataops script runs it:
- Renders any templates for the warehouse and scan files
- Iterates through the scan files specified and executes each
- Returns the test results within the data product platform
- If any Soda Cloud credentials are specified in the warehouse file, it uploads the results to Soda Cloud
Usage
"Soda SQL Testing":
extends:
- .agent_tag
- .should_run_ingestion
stage: "Business Domain Validation Checks"
image: $DATAOPS_SODA_RUNNER_IMAGE
variables:
script:
- /dataops
icon: ${SODA_ICON}
Supported parameters
| Parameter | Required/Default | Description |
|---|---|---|
DATAOPS_SODA_ACTION | REQUIRED | Must be SCAN |
DATAOPS_SODA_WAREHOUSE_PATH | Optional | Path to warehouse YAML file (default is /dataops/soda/snowflake.yml - rendered from /dataops/soda/snowflake.template.yml) |
DATAOPS_SODA_TABLE_PATH | Optional | Path to specific scan files to execute (default is /dataops/soda/tables/) |
DATAOPS_REPORT_DIR | Optional. Defaults to $CI_PROJECT_DIR (Root of the repository) | Path of directory where artifacts are generated |
DATAOPS_REPORT_NAME | Optional. Defaults to report.xml | Name of the XML report generated for tests summary |
DATAOPS_RESULT_NAME | Optional. Defaults to result.json | Name of the JSON result generated by SodaSQL |
Example jobs
A typical pipeline job is structured as follows:
"Soda SQL Testing":
extends:
- .agent_tag
- .should_run_ingestion
stage: "Business Domain Validation Checks"
image: $DATAOPS_SODA_RUNNER_IMAGE
variables:
script:
- /dataops
icon: ${SODA_ICON}
The Soda orchestrator uses a Soda Warehouse YAML file stored at DATAOPS_SODA_WAREHOUSE_PATH.
There are two ways to create this Soda Warehouse YAML file:
- Using a pre-derived fixed-content file found at
$DATAOPS_SODA_WAREHOUSE_PATH - Using Template Rendering to derive the file stored at
$DATAOPS_SODA_WAREHOUSE_PATH
In most cases, you want to leverage template rendering when building a Soda Warehouse YAML. An example file looks like this:
name: { { env.DATABASE } }
connection:
type: snowflake
username: { { SNOWFLAKE.TRANSFORM.USERNAME } }
password: env_var(SNOWFLAKE_PASSWORD)
account: { { SNOWFLAKE.ACCOUNT } }
warehouse: { { SNOWFLAKE.TRANSFORM.WAREHOUSE } }
database: { { env.DATABASE } }
schema: INGESTION
soda_account:
host: cloud.soda.io
api_key_id: { { SODA.API_KEY_ID } }
The name: parameter is important when uploading to Soda Cloud. Using the DATABASE environment variable here automatically namespaces and separates the different environments.
Running subsets of tests
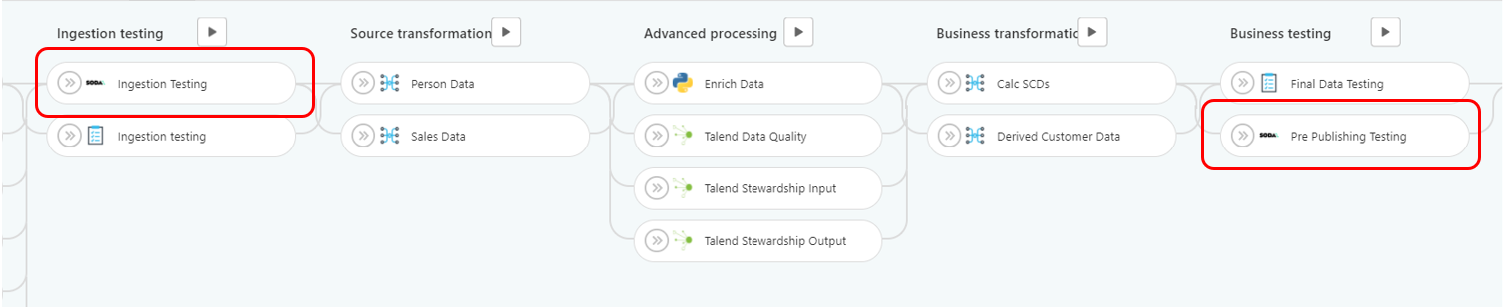
It is critical to run different sets of tests at different stages during a DataOps pipeline run; for instance, one set of tests after ingestion, one at an intermediate step during transformation, and a final set before publication. Soda SQL doesn't support this functionality directly using an approach like tagging; however, it's not difficult to achieve the same thing with directory structures. For example:

To implement the pseud-tagging functionality, sort each of your testing jobs within a specific directory. Each job will then only run the tests located in the particular directory/subdirectory. For instance:
.soda_base:
extends:
- .agent_tag
stage: "Business Testing"
image: $DATAOPS_SODA_RUNNER_IMAGE
variables:
DATAOPS_SODA_SCHEMA: INGESTION
DATAOPS_TEMPLATES_DIR: $CI_PROJECT_DIR/dataops/soda
DATAOPS_SODA_ACTION: SCAN
script:
- /dataops
icon: ${SODA_ICON}
artifacts:
when: always
reports:
junit: $CI_PROJECT_DIR/report.xml
Ingestion Testing:
extends:
- .soda_base
stage: "Ingestion testing"
variables:
DATAOPS_SODA_TABLE_PATH: $CI_PROJECT_DIR/dataops/soda/tables/post_ingestion
Pre Publishing Testing:
extends:
- .soda_base
stage: "Business testing"
variables:
DATAOPS_SODA_TABLE_PATH: $CI_PROJECT_DIR/dataops/soda/tables/pre_publishing
This script will create the following jobs in the DataOps pipeline:
If you configure multiple tests for a single table, Soda SQL doesn't provide the individual time to run each test. This time property is set to the average time to complete all the tests, leading to the incorrect time property value per test.