Data Product Types
Data product types refer to the classification and organization of products based on their characteristics and relationships within a data ecosystem.
DataOps.live data products come in two types depending on their purpose and operational approach. They can be:
- Standalone data products - meet department or team needs.
- Composite data products - meet organizational needs and scale deployment and governance across the enterprise.
Standalone data products
A standalone data product is a self-contained solution that delivers a specific data-related output to meet consumer requirements.
For example, it represents a standalone dataset that could be a set of tables or views. Standalone data products are self-sufficient and usually targeted at a single team or department in an enterprise. They can be simple or elaborate - whereas the latter may have additional methods to consume data.

With the data product platform, you can develop and manage a standalone data product as an independent entity, typically going through its development, testing, deployment, and maintenance lifecycle to ensure accuracy, reliability, and usefulness.
The platform provides specialized capabilities ranging from data ingestion, data quality, and data transformation to data observability and governance necessary to develop and manage data products.
Composite data products
Composite data products are data products assembled from multiple standalone data products.
Composites may integrate diverse datasets, formats, or levels of detail to provide a unified and enriched output. They answer enterprise-level questions by providing a holistic view, enabling cross-functional, cross-domain collaboration while ensuring data governance.
The data product platform offers capabilities, including data product registries, data product dependencies, and a business rules engine to express such dependencies for managing your composite data products.
Standalone data product implementation
Each standalone data product requires a contract, i.e., the properties and metadata providing consumers with essential information to use the data product. Your project's Git repository stores the contract. A Data Product Registry hosts the fully populated contract. You use the contract to manage the development lifecycle of each product. You use the registry to manage your product interdependencies and communication between data products.
Every DataOps pipeline uses a data product contract to build a data product. DataOps pipelines leverage the powerful SOLE and MATE engines and the orchestration capabilities to do so.
Building a data product starts with the data product specification. The specification includes extension points, which pipeline jobs fill with details. At the end of the execution, the Data Product orchestrator generates a data product manifest as a merged document and publishes the manifest into the central registry.

Every time the pipeline runs, it publishes the latest manifest with the required details you can extend to anything you want.
When you define the data product in the specification file, you must manually run the pipeline for the first time to register all information before it is automatically triggered as per the rules in the specifications.
The data product workflow goes through the following steps from specifications to manifest:
- The data product engine initiates processing according to the data product specification by triggering pipelines per the specification rules.
- The data product specification, stored in the project repository, holds the base definitions and extension points, which pipeline jobs populate.
- During the pipeline execution, the specification is validated, enriched with metadata, and deployed to the data product registry.
- Jobs adds the dataset's metadata to the source specification.
- The Data Product orchestrator eventually uploads the merged manifest to the data products registry.
- Optionally, a data catalog shows the data product dependencies and becomes the source of truth, ensuring a single definition of a standard concept.
You can manage access to data products by creating the registry at different levels of the hierarchy, i.e., domain, group, subgroup, or individual projects. The registry placement decides who can have access to its data products.
Data product specification
A data product specification is a document that outlines the data product's characteristics, functionality, and requirements. It is a comprehensive document that provides clear instructions and guidelines for building and implementing the data product.
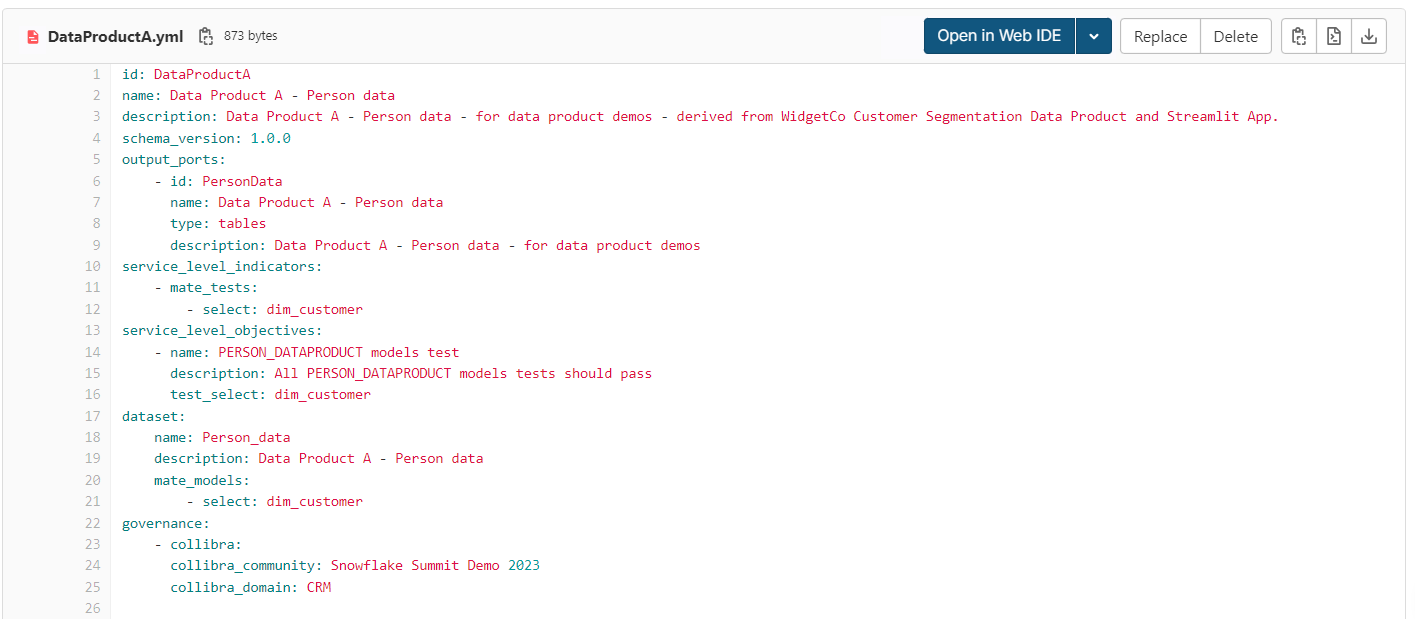
DataOps.live provides a data product specification file stored inside the project. This file contains all the input information necessary to build the data product, name, description, version, output ports, SLOs, etc. But this file does not have all the detailed information required on the output side. As the pipeline runs, jobs populate the data product manifest with detailed information. All jobs can read the specification.
What is included in the specifications?
A typical data product specification file should include at least the following components:
- Unique ID, name, and description to provide context
- Input ports and trigger rule and actions (where rules are the refresh conditions that must be in place for the refresh of this product to occur)
- Datasets
- Output ports
- Service Level Objectives (SLO)
- Service Level Indicators (SLI)
Versioning specifications
You can and should have multiple data product specification files. Each file defines one version. Multiple schema versions must exist in the same project version - they cannot be in different branches or tags.
The data product version differs from another version in at least one of the following:
- Dataset - metadata of tables and views that are part of the data product
- The name, semantics, and data type of the SLOs
- The name, semantics, and data type of the SLIs
Data product manifest
A data product manifest is a document that outlines the properties and metadata of a data product, providing consumers with essential information on how to use it within their workflows or applications effectively.
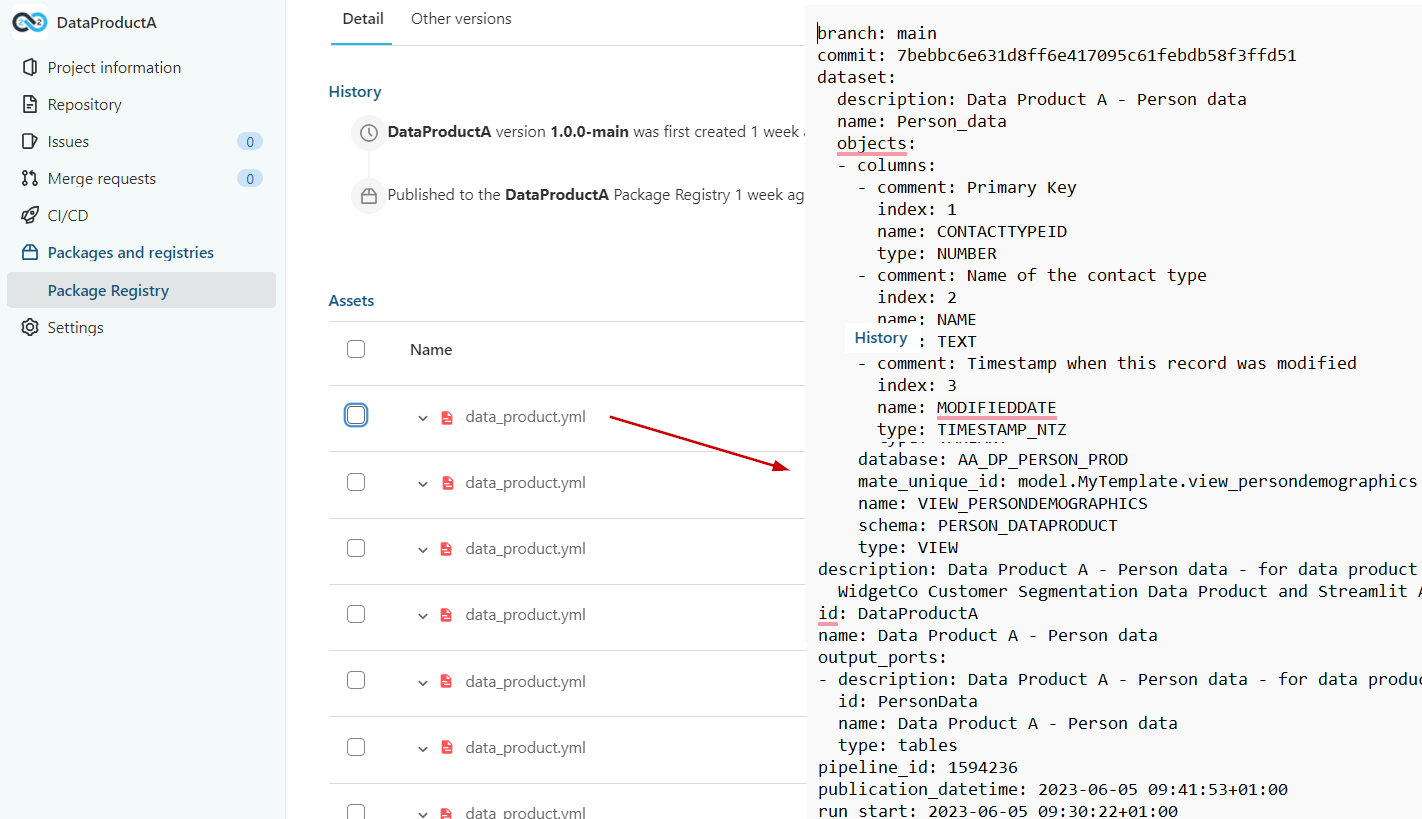
DataOps.live provides a data product manifest document stored in the data product registry.
A DataOps pipeline starts from the data product specification. During the pipeline run, any job can create data product snippets. At the end of the pipeline, the Data Product orchestrator produces the data product manifest from the specification and the data product snippets.
A pipeline can produce more than one snippet. And a particular job can produce more than one snippet as well.
Composite data product implementation
Implementing a composite data product is based on the data product dependencies. Data product dependencies refer to the relationships and interdependencies between different data products organized hierarchically within an ecosystem.
DataOps.live provides the framework to manage data product dependencies using a specifications file, registry, and manifest for each data product. A DataOps pipeline uses the Data Product Specifications and interdependencies to build the data product, create a data product manifest, and publish it into the central project registry, allowing communication among all data products.
In this hierarchy, data products are arranged in levels, starting from the source data products, followed by intermediate data products, and finally leading to consumer-facing data products. Each level in the hierarchy is a building block for the subsequent level, providing processed, transformed, or aggregated data that is further refined or used by the higher-level data products.
Running DataOps pipelines results in building data products, updating them, and refreshing their data to create different versions of the data products once there are any changes.
This framework helps manage the development lifecycle seamlessly through the DataOps pipelines, all undergirded by the powerful SOLE and MATE engines and the orchestration capabilities.