Setting Up DataOps.live and Snowflake
Overview
The implementation of DataOps.live involves different planes in which both DataOps.live and customers collaborate to establish a suitable infrastructure and use the data product platform to develop, branch, and deploy code and data.
- The data plane handles the actual processing and manipulation of data.
- The control plane coordinates and orchestrates data operations.
- The management plane oversees the administration and governance of the DataOps environment.
These three planes work together to enable effective data management, processing, and operations within a DataOps framework.

The following topics describe setting up the DataOps.live infrastructure.
Setup checklist
This checklist outlines the main steps to set up your DataOps.live infrastructure, ensuring that you have the necessary accounts, configurations, and components in place to begin using DataOps.live effectively.
- Set up DataOps.live account to start managing your Snowflake data with Dataops.live.
- Set up Snowflake account with the role, warehouse, and main user properties.
- Populate secrets to securely connect your DataOps infrastructure component.
- Set up runners to execute DataOps pipelines.
Step 1 - Set up DataOps.live account
-
The DataOps.live team sets up the top-level DataOps group.
-
Your first project is either done by the DataOps.live team. Alternatively, you can do it in less than a minute.
-
Once the project is created:
-
Edit
pipelines/includes/config/variables.ymland set:DATAOPS_PREFIXto a prefix defining the scope of your project that will serve as a prefix for most objects inside Snowflake. For a demo, you can leave the default valueDATAOPS.warningSupported characters in
DATAOPS_PREFIXare letters (A-Z), decimal digits ( 0-9), and an underscore (_). If lowercase letters are used, SOLE adds a prefix and suffix to the value of the variableDATAOPS_DATABASEavailable at pipeline run time to create a default database with an incorrect name.DATAOPS_VAULT_KEYto a long random string
-
Edit
pipelines/includes/config/agent_tag.ymland set the tag to something we will use later when setting up the DataOps Runner, e.g.pipelines/includes/config/agent_tag.yml.agent_tag:
tags:
- dataops-production-runner
-
-
Define additional users for your project. You will need to provide a list of names and email addresses to DataOps.live.
Step 2 - Set up Snowflake account
You need a Snowflake account with the role, warehouse, and main user properties to start using DataOps.live and managing your Snowflake data and data environments.
Our data product platform uses the DataOps methodology in the Data Cloud and is built exclusively for Snowflake. To complete the setup of the DataOps.live infrastructure, creating a Snowflake account is essential.
This will be your main Snowflake account (or accounts) for production. However, for PoC purposes, it can often be quicker to create a disposable account at signup.snowflake.com.
A user with the ACCOUNTADMIN role is needed to run the setup SQL.
Prerequisites
Enter your password in the PASSWORD field before running the script below to create the Snowflake instance.
Configuring a new Snowflake account
Adjust the below SQL for the trial account and according to your configuration:
---- ROLES ----
-- Admin role (DATAOPS_SOLE_ADMIN_ROLE)
USE ROLE SECURITYADMIN;
CREATE OR REPLACE ROLE DATAOPS_SOLE_ADMIN_ROLE;
USE ROLE ACCOUNTADMIN;
GRANT
CREATE DATABASE, -- CREATEs needed for SOLE object creation and management
CREATE USER,
CREATE ROLE,
CREATE WAREHOUSE,
CREATE SHARE,
CREATE INTEGRATION,
CREATE NETWORK POLICY,
MANAGE GRANTS -- MANAGE GRANTS needed to allow SOLE to manage users (specifically so it can SHOW USERS internally)
ON ACCOUNT TO ROLE DATAOPS_SOLE_ADMIN_ROLE;
GRANT ROLE DATAOPS_SOLE_ADMIN_ROLE TO ROLE SYSADMIN; -- or to the most appropriate parent role
---- WAREHOUSES ----
CREATE WAREHOUSE DATAOPS_SOLE_ADMIN_WAREHOUSE WITH WAREHOUSE_SIZE='X-SMALL';
GRANT MONITOR, OPERATE, USAGE ON WAREHOUSE DATAOPS_SOLE_ADMIN_WAREHOUSE TO ROLE DATAOPS_SOLE_ADMIN_ROLE;
---- USERS ----
-- Main user
USE ROLE USERADMIN;
CREATE OR REPLACE USER DATAOPS_SOLE_ADMIN
PASSWORD = '' -- Add a secure password here, please!
MUST_CHANGE_PASSWORD = FALSE
DISPLAY_NAME = 'DataOps SOLE User'
DEFAULT_WAREHOUSE = DATAOPS_SOLE_ADMIN_WAREHOUSE
DEFAULT_ROLE = DATAOPS_SOLE_ADMIN_ROLE;
USE ROLE SECURITYADMIN;
GRANT ROLE DATAOPS_SOLE_ADMIN_ROLE TO USER DATAOPS_SOLE_ADMIN;
GRANT ROLE ACCOUNTADMIN TO USER DATAOPS_SOLE_ADMIN; -- Needed for creating resource monitors
Using an existing Snowflake account
If you want to use an existing Snowflake account, see Privileges for a Fresh Environment and Privileges to Manage Preexisting Objects.
Step 3 - Populate secrets
To connect to Snowflake, you need to set four DataOps Vault keys. The DataOps Secrets Manager Orchestrator is fully documented in this section. This guide assumes that:
- If using AWS, the DataOps runner uses an IAM role attached to your EC2 instance, which has the relevant access to read the keys from the secrets manager or the SSM parameter store.
- If using Azure, the DataOps runner uses a service principal attached to your Azure VM, which has the relevant access to read the keys from the KeyVault.
Using AWS secrets manager
If you are using AWS Secrets Manager, your configuration should look something like this (with your details substituted):
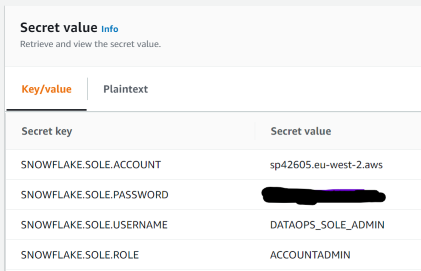
SNOWFLAKE.SOLE.ACCOUNT
SNOWFLAKE.SOLE.PASSWORD
SNOWFLAKE.SOLE.USERNAME
SNOWFLAKE.SOLE.ROLE
SNOWFLAKE.SOLE.WAREHOUSE
and in your pipelines/includes/config/variables.yml include:
variables:
...
SECRETS_SELECTION: <the name of your secret>
SECRETS_AWS_REGION: <the AWS region for your secret>
Using AWS SSM parameter store
If you are using the AWS SSM Parameter Store, your configuration should look something like this (with your details substituted):
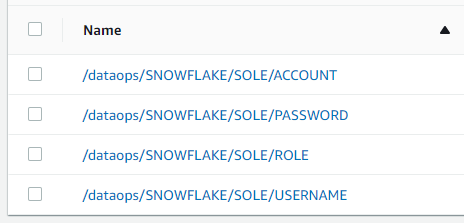
/dataops/SNOWFLAKE/SOLE/ACCOUNT
/dataops/SNOWFLAKE/SOLE/PASSWORD
/dataops/SNOWFLAKE/SOLE/ROLE
/dataops/SNOWFLAKE/SOLE/USERNAME
/dataops/SNOWFLAKE/SOLE/WAREHOUSE
and in your pipelines/includes/config/variables.yml include:
variables:
...
SECRETS_MANAGER: AWS_PARAMETER_STORE
SECRETS_SELECTION: /dataops/SNOWFLAKE/SOLE/
SECRETS_STRIP_PREFIX: /dataops/
Using Azure KeyVault
If you are using Azure KeyVault, your configuration should look something like this (with your details substituted):

SNOWFLAKE-SOLE-ROLE
SNOWFLAKE-SOLE-PASSWORD
SNOWFLAKE-SOLE-USERNAME
SNOWFLAKE-SOLE-ACCOUNT
SNOWFLAKE-SOLE-WAREHOUSE
and in your pipelines/includes/config/variables.yml include:
variables:
...
SECRETS_MANAGER: AZURE_KEY_VAULT
SECRETS_AZURE_KEY_VAULT_URL: https://KEY_VAULT_NAME.vault.azure.net/
Step 4 - Set up a runner on AWS EC2 and EKS or Azure VM
You must install a runner to make the most of DataOps.live. The runner is a key component that helps run pipelines smoothly. Failure to install a requestAnimationFrame will hinder the functionality and performance of the DataOps.live data product platform.
Follow the steps in Docker Runner Installation or Kubernetes Runner Installation to install and configure a DataOps runner for your compute environment. As part of the installation, the runner is associated with your group (preferred) or project in the data product platform.
Testing your project and creating development environments
At this stage, you're ready to run the DataOps project using the full-ci.yml pipeline.
To run your first pipeline:
- In your Dataops project, hover over CI/CD in the left-hand navigation and select Pipelines from the dropdown.
- Once on the pipeline page, click Run Pipeline in the upper right to open the run pipeline page.
- On the run pipeline page, select
full-ci.ymlfrom the Pipeline type dropdown and then click Run pipeline at the bottom of the form to start the pipeline.
The Snowflake Object Lifecycle Engine (SOLE) creates some base infrastructure. Now that you have a fully functional DataOps pipeline, you can explore further as below:
- Create a
qabranch frommainand run thefull-ci.ymlpipeline in this branch. This creates a QA environment in Snowflake. - Create a
devbranch frommainand run thefull-ci.ymlpipeline in this branch. This creates a DEV environment in Snowflake. The DEV database will be created from the PROD database using zero-copy clones. - Create a
my-first-featurebranch fromdevand run thefull-ci.ymlpipeline in this branch. This creates a feature branch environment in Snowflake. The DEV database will be created from the PROD database using zero-copy clones.
See DataOps Environments for more information on the environments used with DataOps.live, and DataOps Sample Development Workflow for a usage example.